Glove,基于全局词频统计的词嵌入方法。来自EMNLP,2014。原文。code。
概述
单词嵌入的两个主流方法是,如LSA的全局矩阵分解方法,和局部上下文窗口方法(CBOW,skipgram)。前者在单词类比任务上较差,后者无法在全局共现次数上进行训练。
本文提出了一个全局对数双线性回归模型Glove,其通过在单词共现矩阵的非零元素上来学习单词的向量表示,其结合了全局矩阵分解和局部上下文窗口的方法,在词类比任务上仍有较好的性能,并且在一些其他任务上优于其他模型。
模型
设定词词共现矩阵 X ,x_ij 表示词 j 在词 i 上下文出现的次数,X_i =∑k X_ik 表示任何单词在单词 i 出现在上下文的次数,设 P_ij = P( j |i) =X_ij /X_i ,表示单词 j 在 i 上下文出现的概率。
我们使用共现概率的比值来表示词的关系
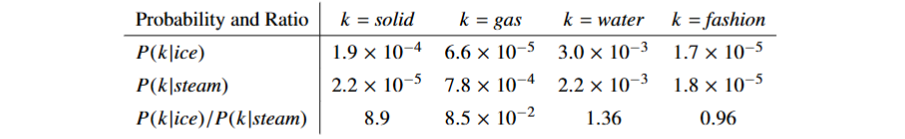
如上,同为热力学名词的ice 和 stream,引入额外的单词k,我们考虑二者与其共现概率的比值,当 k=solid,其与ice强相关,与stream弱相关,相应的共现概率的比值很大(8.9);当k=gas,同理,比值很小(0.085),当k二者都相关;如water,或者都不相关,如fashion,比值则接近1。
因此网络学习的起点应该是共现概率的比例,其由三个单词(的嵌入)决定。最一般的模型如下定义。
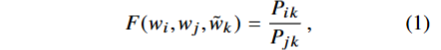
等式右侧有语料库决定,左侧的F函数是什么呢?
首先,F需要对线性向量空间中存在共现概率比值的信息编码,不妨考虑两个目标词的差异,修改等式如下。
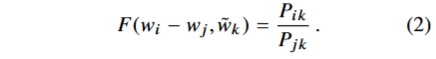
其次,F的参数是向量,结果是标量,为了使其统一,我们引入点积。
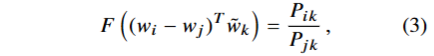
词共现矩阵是无序的,因此上式需要具有一定程度的对称性。满足对称性有两个条件,第一,F需要是群 (R, +) 和 (R>0, ×)的同态( f(a⋅b)=f(a)∗f(b) ),即要满足
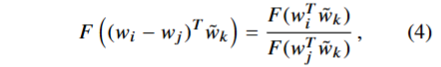
由(3)可知,分子为
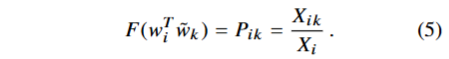
满足(4)的 F 可以是指数函数,即
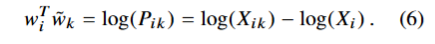
观察到由于最后一项的存在,(6)式不对称。又因为其与k无关,因此将其视为wi的参数(偏置)bi,最后增加一个额外的偏置bk,使得wk,wi对称。
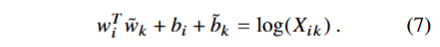
我们得到了(1)的变化式(7)。然而(7)在 X_ik = 0处发散,解决这一问题的方法是添加偏移
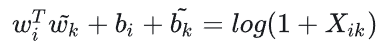
还有一个问题是,模型将所有共现视为等价的,然而矩阵是很稀疏的,0元素通常占到 75% - 95% 的比例,因此我们不选用上述的加法等式,而是在loss上引入一个权重函数 f() ,最终的loss为
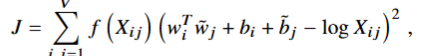
其中 f() 要满足,f(0) = 0 ;f(x -> 0) = 0;应该是非递减的,因此可以降低罕见共现的影响;在X较大时应该趋于平缓,从而不会出现共现分配过重的情况。本文选取的 f()如下。
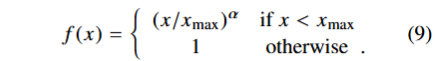
其图像
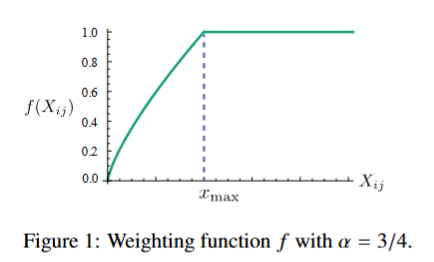
实验中,x_max = 100,a = 3/4。
模型复杂度分析
实验
实验方法
(实验中涉及的具体模型配置详见原文)
词类比任务
该任务旨在回答问题“a is to b as c is to ??。" 通过根据余弦相似度找到表示 wd 最接近 wb − wa + wc 的词 d。在词类比任务上的不同模型的数据如下,其中Sem.代表语义得分,Syn.代表句法得分,Tot.代表总分。
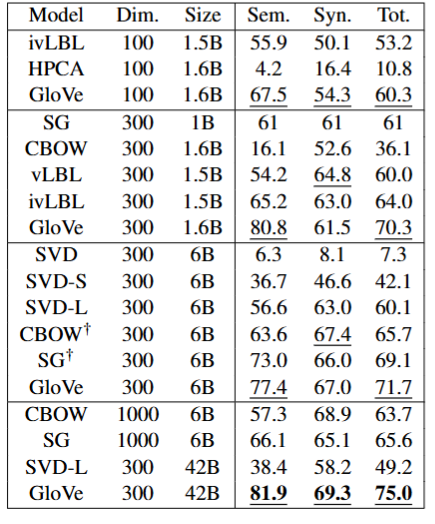
可见
- Glove模型性能明显优于baseline。
- 增大语料库并不一定能带来性能的增加(如SVD),而Glove在4亿的语料库上表现很好,这也证明了共现加权的必要性。
单词相似度任务
在五个不同的单词相似度数据集进行模型比较,其中所有模型的维度都是300维,结果如下。
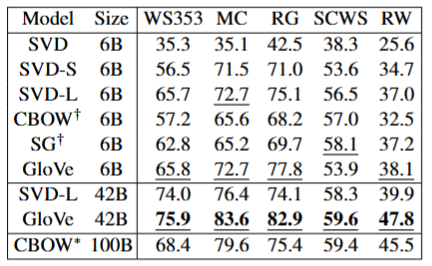
可见,Glove优于在100B数据训练的CBOW模型。
NER
使用BIO2标注数据,结合CRF进行序列预测,下图展示了各模型的结果。
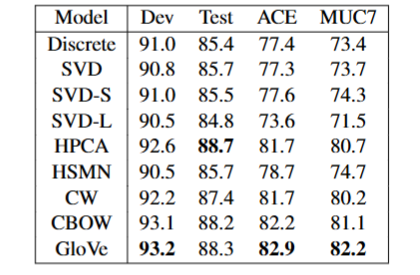
训练细节
语料库的信息和实验细节暂略。
模型分析
模型参数
我们分析不同向量长度和上下文大小带来的模型影响
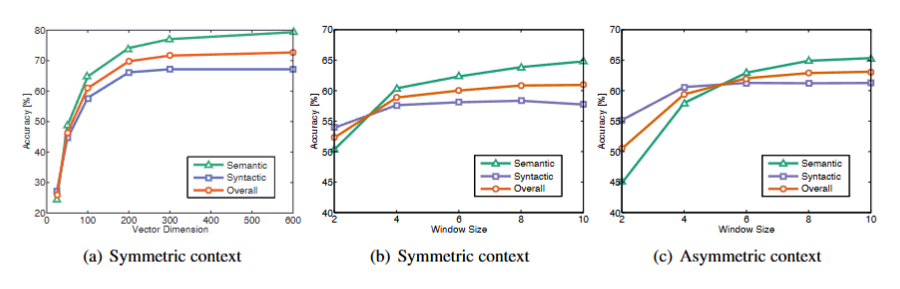
在(a)中,窗口大小为10,(b)(c)中向量大小为100,symmetric指扩展目标次左右的上下文窗口,asymmetric指进扩展目标左侧的窗口。
可见,
- (a)中,向量长度大于200时收益递减
- 对于小型非对称窗口,句法任务更好,这与句法信息主要来源于直接上下文并且强依赖于语序的直觉是一致的。
- 语义信息往往是有更大的窗口大小捕获的
语料库大小
在不同语料库训练的300维向量但词类比性能如下
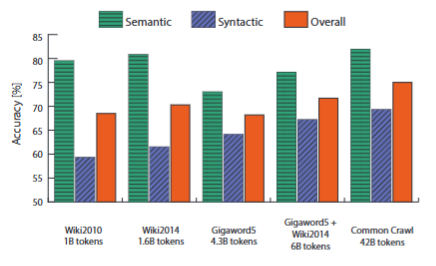
可见,
- 句法子任务的性能随语料库大小单增
- 然而语义子任务的性能并非如此,其在维基百科数据集上的表现很好,或许是因为该数据集中有大量的关于类比数据的样本,并且危机可以随时更新,而gigaword5 不具备上述的特点。
运行时间
学习曲线图见下一节。
与w2c对比
理论上,二者的对比是很困难的,因为很难去控制变量。我们假定其他参数都是默认的最优,制图如下。
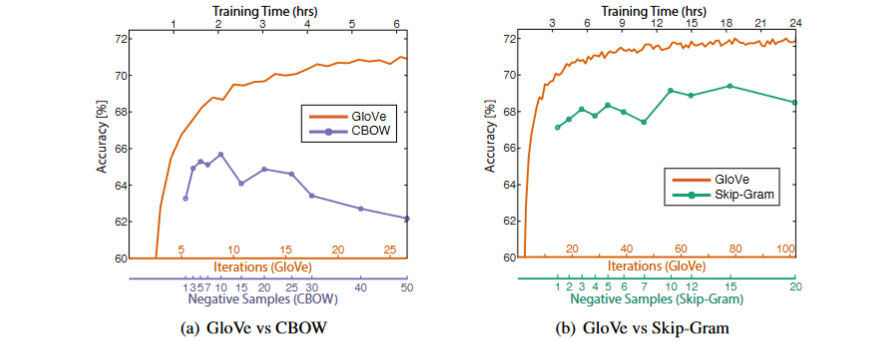
底部的两个 x 轴表示 GloVe 的相应训练迭代数和 word2vec 的负样本。我们注意到,如果负样本的数量增加到大约 10 之外,word2vec 的性能实际上会降低。据推测,这是因为负采样方法不能很好地近似目标概率分布。
对于相同的语料库、词汇、窗口大小和训练时间,GloVe 始终优于 word2vec。它更快地取得了更好的结果,并且无论速度如何,也获得了最好的结果。