word2vector的开山之作,来自ICLR,2013。原文。code。
概述
介绍 word2vector 的两种架构(cbow以及skip gram),word2vecotr用被于获得单词的向量表示。其下相比于之前的神经网络使用了更低的成本取得了更高的准确性。
具体来说,文章主要分为三个部分
- 提出新的模型架构来获得准确的向量表示,“准确”指在采用较低的嵌入维度表示单词时,不仅仅相似的单词具有相近的位置,而且可以有着多维度的相似性(king-man+queen=woman)。
- 设计了新的测试集
- 讨论了训练时间和准确性如何取决于词向量的维度和训练数据量
首先定义模型的计算复杂度,
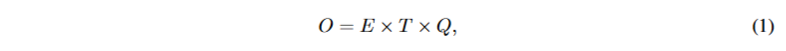
其中 E 是训练时期的数量,T 是训练集中的单词数,Q 进一步为每个模型架构定义。常见的选择是 E = 3 - 50 和 T 高达 10 亿。
1 | 所有模型都使用随机梯度下降和反向传播 |
NNLM
NNLM的模型具体结构请见论文1,概不赘述。其每个训练样例的计算复杂度为。词表数V,隐藏层H,编码单词N,
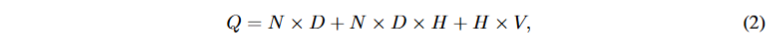
Recurrent NNLM
RNNLM可以解决NNLM的一些限制。其复杂度为
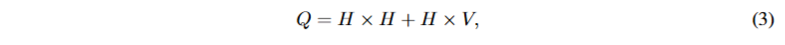
log-linear model
NNLM中,复杂度主要是由非线性隐藏层引起的,因此尝试去掉他。
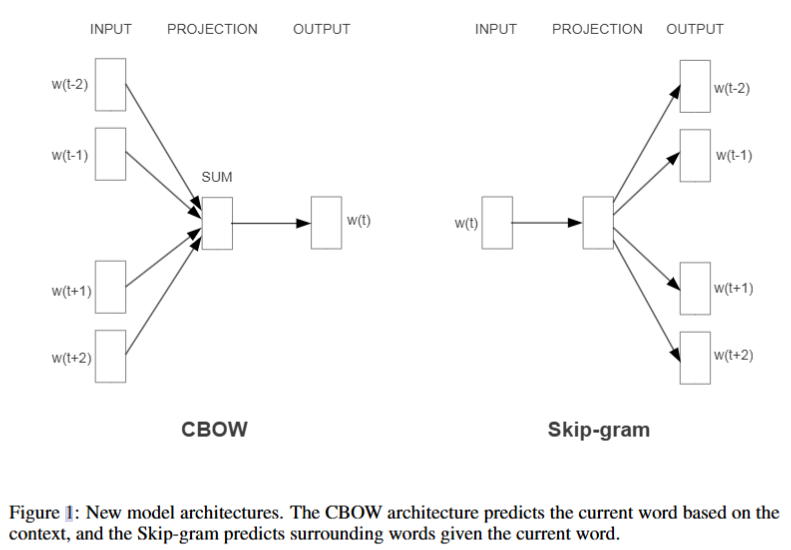
CBOW连续词袋模型
CBOW类似于feedforward NNLM,其删除了非线性隐藏层,并且所有单词共享投影层。模型使用未来和过去的词构建一个对数线性分类器,旨在正确分类中间的词。其复杂度为
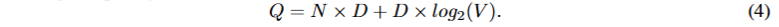
skip-gram模型
sjip-gram于CBOW类似,只不过CBOW根据上下文预测单词,而skip-gram把单词作为投影层的对数线性分类器的输入.并预测其前后一定范围的单词。其复杂度为
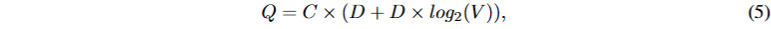
C是预测的前后距离。
实验
实验中更专注于比较相近单词在多维度上的相似性,比如问题被设计为:哪个词在与small的相似度上接近bigger与big的相似度?具体通过向量加减法实现,并选择与答案余弦相似度最高的预测。
测试集
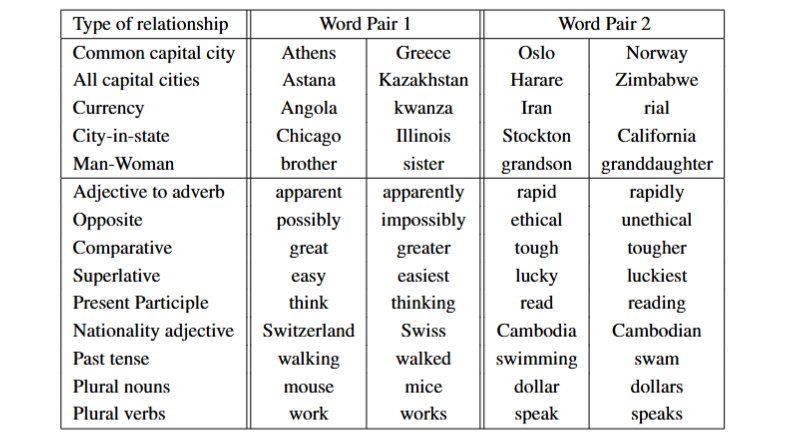
测试集的示例如下,5种语义关系共8869个,9种句法关系共10675个。
我们评估所有问题类型的准确性,只有在预测的词完全与答案相同时才认为是正例
训练集
训练集来自谷歌新闻预料,100w个常用词。为了快速估计模型架构的最佳选择以获得尽可能好的结果,首先评估了在训练数据子集上训练的模型,词汇量限制为最频繁的 30k 个单词。
结果
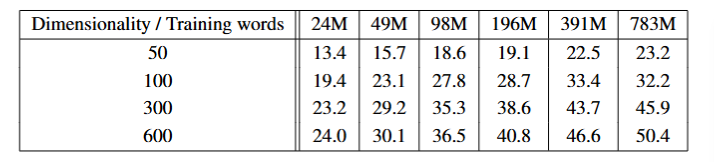
在测试集的子集上的单词测试问题,不同维度的嵌入向量和训练数据的CBOW模型ACC如下。可见在某个点后,单独增加维度或者训练数量准确率不会有大幅增加,因此我们需要同时提高二者。
对比
我们比较640维情况下的不同模型(测试集也做了调整,详见原文)
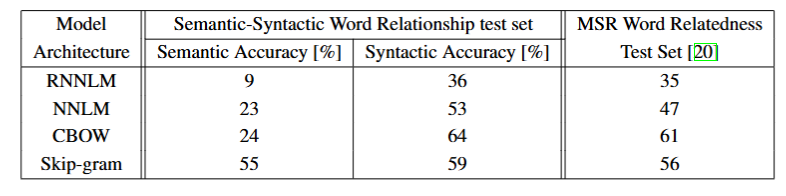
评估了仅用一个CPU训练的模型,并将结果与公开可用的词向量进行了比较如下
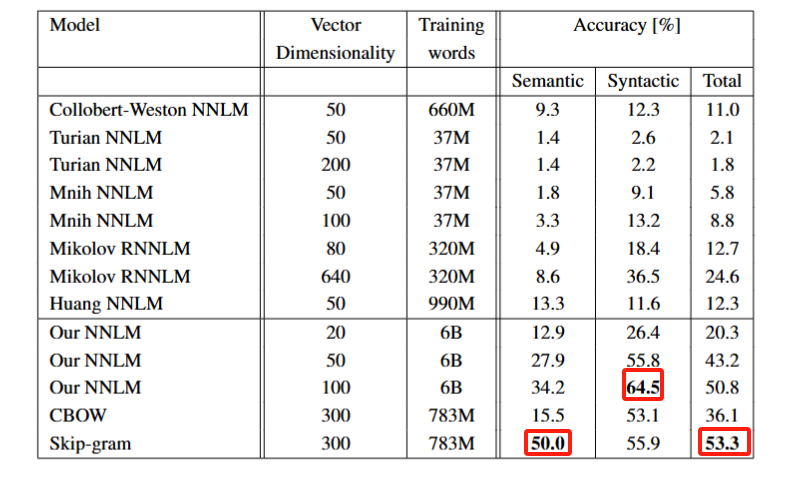
后续实验仅使用了一个epoch,我们将其与之前3个epoch的训练比较,可见,使用两倍数据的一个epoch相较于一倍数据的3个epoch有更好的结果和速度。
大规模并行训练
算力问题,略。
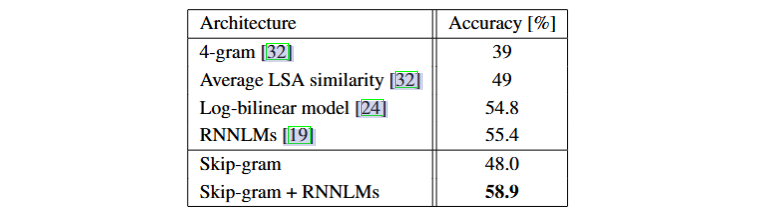
Microsoft Sentence Completion Challenge
微软句子完成数据集
关系的学习
如下图展示了各种关系
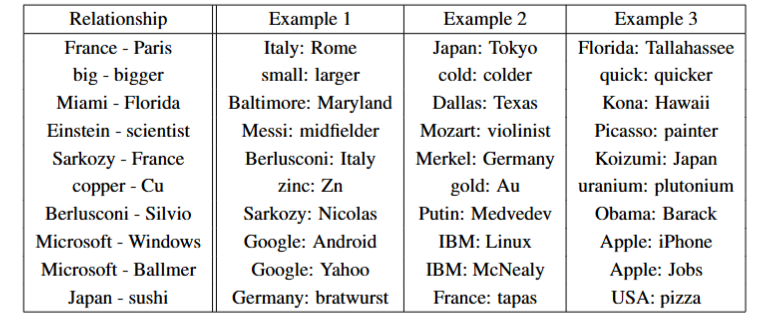
关系是由词对的向量对相减得到的,这也是我们之前实验的基础,然而如前所示准确率只有60%,或许在更大的数据集和更高的维度上性能会得到显著提高。
提高性能还可以通过使用多个关系实例,将多个向量取平均得到关系向量。
值得一提的是,我们处理不在列表中的词向量的方法是,将表内所有的但词向量取平均,再找到距其最远的词向量。