GNN的入门博客笔记,主要参考了这篇博客。
- 引言
- 图
- 图问题
- GNN
- other graph
- sampling graph & batching
- inductive bias 归纳偏好
- aggregate operation
- GCN
- 边和图的对偶
- 矩阵与图
- GAT
- Explain & attributions
- generative modling 图生成
引言
一组对象及其链接自然的表示一个图,而在图数据上操作的神经网络称为图神经网络(GNN)。近些年GNN在ai4science,交通预测,recommandation system有着广泛的应用。
本文将从四方面展开。一,图是什么;二,图数据的特点;三,构建一个GNN;四,GNN playground。
图
图具有三种属性,节点,边,以及全局图。他们内部可以储存相关的信息——标量或者嵌入(embed ing)。
图有着强大的数据表示方式,甚至能违背直觉地表达文本和图像。
我们通常图像看作有多通道的矩阵网格,通过多维数组存储。我们可以将其视为具有规则结构的图,每个像素代表一个节点,边连接相邻的元素。如下。
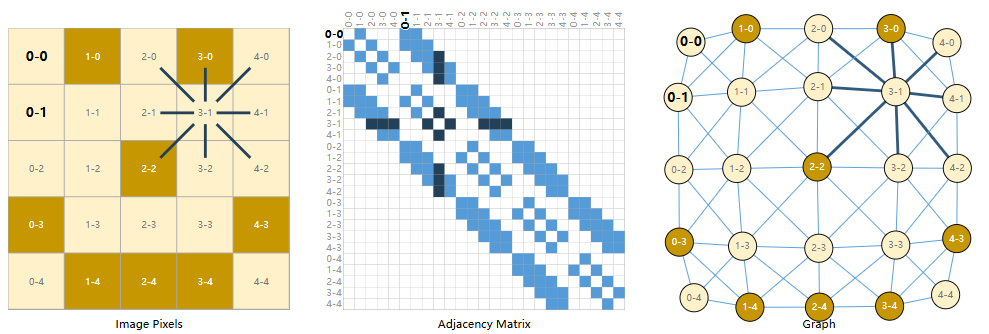
可见非边缘节点总有八个邻居,而每个节点储存着RGB三维向量。
对于文本,通过索引链接每个token,构建了一个有向图。如下。
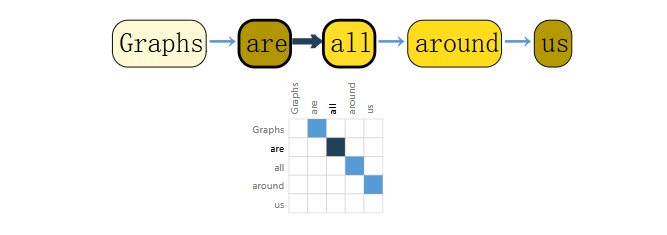
可见,每个节点储存token,并通过边链接语义顺序。
但通常图文并不会如此表示,实在太过冗余。
1 | 上述的文本有向图指的是RNN处理的序列,而在tf中,将其视为完全链接的图。 |
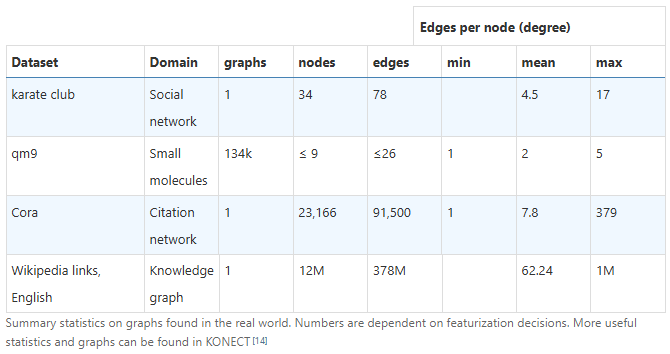
上述的图节点和便具有相同的结构,我们称其为同构图。如果每个结点的邻居数量可变,我们称其为异构图。比如说分子,社交网络,引用网络,cv中的场景对象,方程变量的数据流图。
实际应用中,不同类型数据的图结构有着很大差异,有点的点多变少,有些恰恰相反。
图问题
图上有三种一般任务,图级(图分类),节点级(节点分类),边级(边预测)。
在深度学习中,如何表视图数据是关键。要表示节点,边,全局上下文,和连通性。前三者可以采用矩阵存储,然而连通性如果采用邻接矩阵,其可能会达到很大的空间复杂度,并且很稀疏。其次,邻居矩阵并不唯一,结点的编号改变会得到不同的邻接矩阵,但是无法使得不同的矩阵在网络中产生相同的结果。
一种方法是采用邻接表表示,可以大大的降低空间复杂度。
GNN
GNN接受图输入,输出图,对其属性嵌入进行运算,而不改变本身的连通性结构。
对每个属性使用MLP计算,称之为GNN层,GNN层叠加构成了传统的神经网络模块。
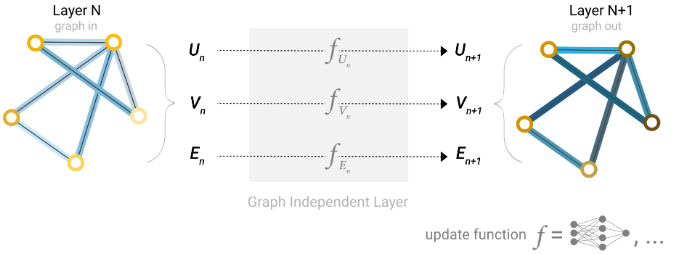
pooling
对于一个简单的二分类任务,以节点分类为例,只要对每个节点嵌入运用线性分类器即可。然而,如果图中不含有节点信息而需要利用便信息进行预测,我们需要将边上的信息传递给节点,称之为池化,pooling。
pooling首先对每个要pool的属性收集embedding并concatenate为矩阵,再通过某种sum operation将其aggregate。
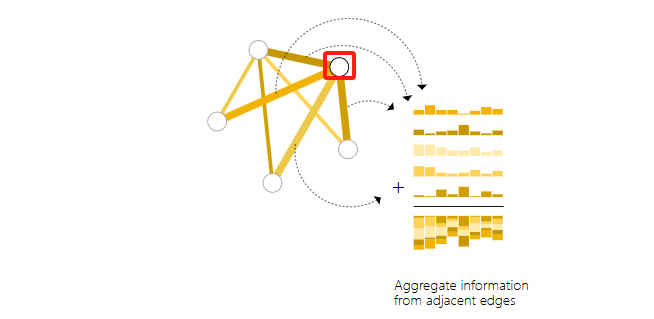
可见,我们可以通过pooling对不同属性进行消息传递,从而进行分类任务。这是构建复杂GNN的基础。
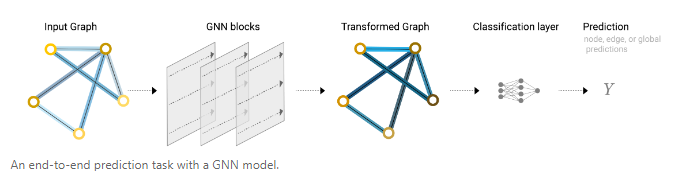
消息传递
message passing使得在GNN内使用pooling使用的嵌入更好地表示图的结构。message passing的步骤如下。
- 对于图中每个节点收集所有相邻节点的嵌入(消息)
- 通过一个aggregate function聚合所有消息
- 所有获得的消息通过一个update fuction,即神经网络。
message passing也可以用于节点和边。
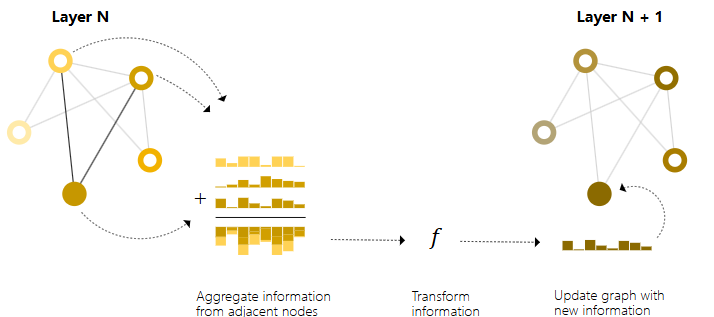
通过堆叠GNN的message passing层,一个节点最终可以整合整个图中的信息,在三层之后,一个节点具有离他三步远的节点信息。
edge representations
使用pooling在模型最终的预测步骤将信息从边传递到节点。此外还可以在GNN内使用message passing在节点和边之间共享信息。这与节点之间的方法类似——收集边的信息,再通过update function转换并存储它。一个问题是,节点和边信息不一定相同,因此要学习一个点空间到边空间的线性映射,或者在update function之前将二者concatenate。
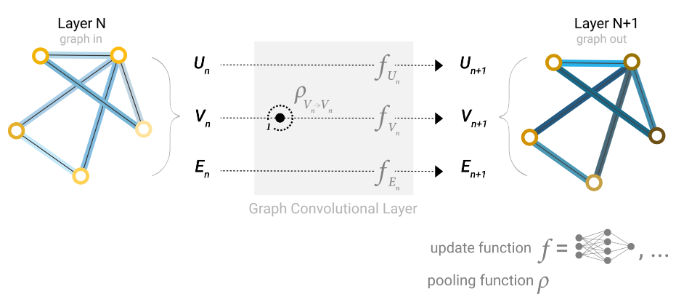
构建GNN时,我们需要考虑更新那些图属性以及更新它们的顺序,例如,我们可以采用weave的方式更新,
包含点到点,边到边,节点到边,边到节点。
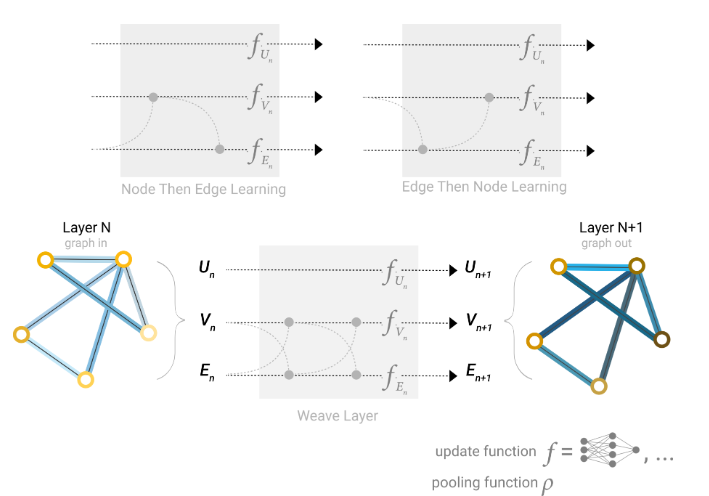
global representations
之前所描述的网络,当图中节点间距较远时可能无法有效传递信息,k层的GNN只能传递k步远,这在预测任务依赖于相距较远的节点或节点组的情况下可能会成为一个问题,一个解决方案是让所有节点能够互相传递信息。然而,对于大型图这是不现实的。
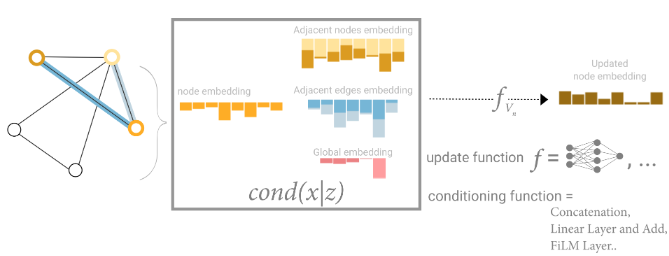
因此我们使用图的全局表示(U),有时称为master node 或者context vector(上下文表示),其能连接到图中的其他所有节点和边,并作为它们之间的消息桥梁。
因此,途中的所有属性都有了学习到的embedding,使用pooling将他们整合,可以再更新节点embedding时考虑其他属性的信息。具体来说,方法有,concatenate;通过线性映射使它们映射到同一个向量空间再相加,这样可以确保信息在同一尺度上融合;使用feature-wise modulation layer(特征层调制层),这是一种特征级别的注意力机制。
GNN playground
这篇博客可视化了一个判断化学结构是否具刺鼻气味的GNN网络,并且可以自定义模型参数。可以在网站上
自行尝试不同的架构。
GNN设计的经验之谈
GNN层数越深越好吗?aggregation function该怎样选?答案是取决于数据的。甚至不同的特征化和构建图方法也会带来差异。
下图是一个训练变量数量-性能的图,可见参数数量确实与性能正相关。
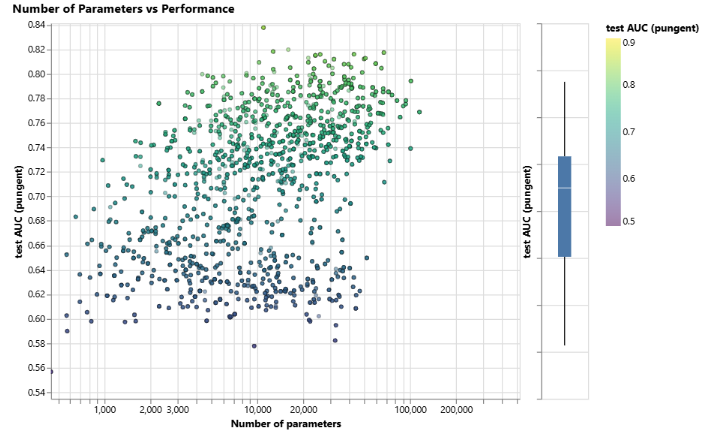
可见,GNN是一种很高效的模型,即使参数数量很少(3k),也能找到性能较好的模型。
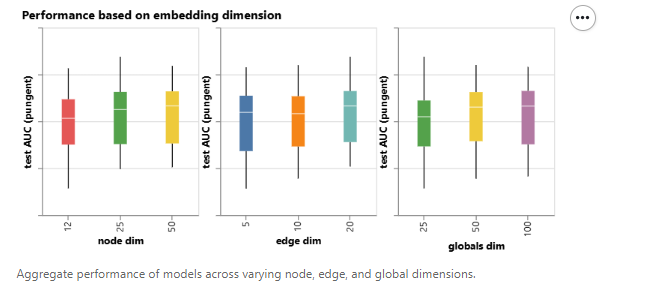
接下来,我们可以看一下基于不同图属性的学习表示维数聚合的性能分布。我们可以注意到,具有更高维数的模型往往具有更好的平均和下限性能,但最大值的趋势并不明显。一些表现最好的模型可以在较小的维度中找到。由于较高的维数也会涉及更多的参数,这些观察结果与前一个图表是一致的。
接下来,我们可以看到基于 GNN 层数的性能分解。箱线图显示了一个类似的趋势,虽然平均性能随着层数的增加而增加,但表现最好的模型并没有三层或四层,而是两层。此外,四层的性能下限下降了。之前也观察到了这种效果,具有更多层数的 GNN 将在更远的距离上传播信息,并可能由于多次连续迭代而导致节点表示的‘稀释’。
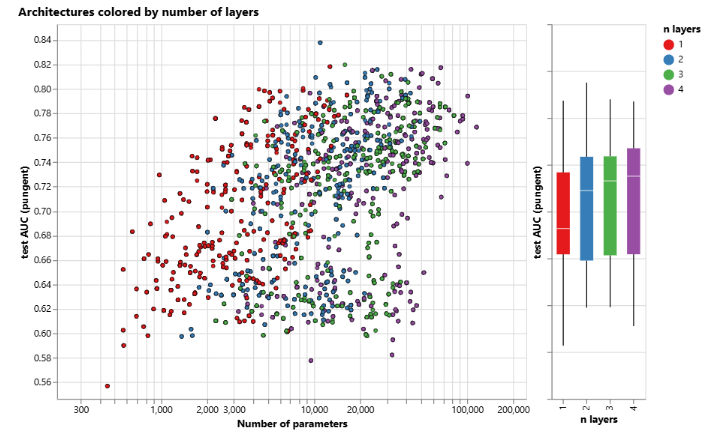
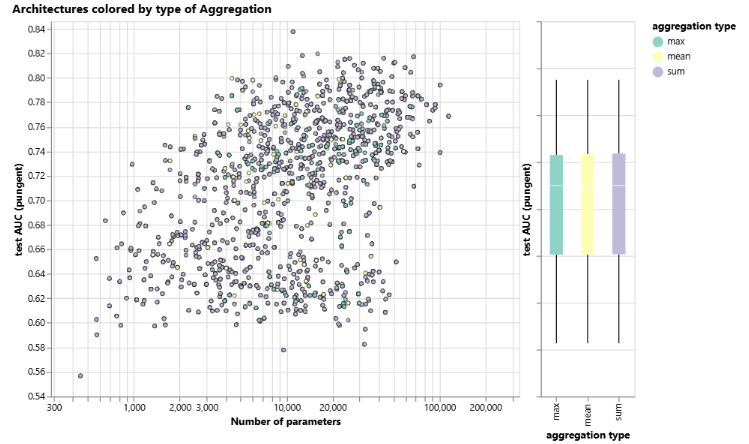
下图按聚合类型分解性能。总体来看,求和在平均性能上略有改善,但最大值或均值也可以产生同样好的模型。这在考虑聚合操作的区分/表达能力时很有用。
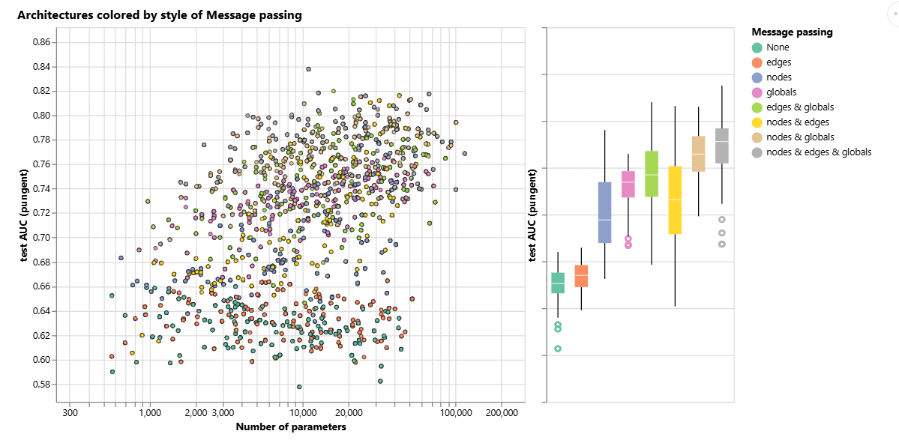
消息传递?图属性之间的通信越多,平均模型的性能越好。我们的任务集中在全局表示上,因此显式地学习这一属性也倾向于提高性能。我们的节点表示似乎比边表示更有用,这也很合理,因为节点属性中加载了更多信息。
上述讨论有着如下的启发,想要提高模型的性能,有两个通用的方向:一是选择更复杂的图算法,二是设计图本身。上述的GNN都依赖于pooling,但是有些图(比如线型图路径)就很难采用这种方式。因此需要设计新的机制,使得图信息在GNN中提取执行和传播。
正如上图所见,图属性的message passing越多,模型的表现越好,因此如何构建图很重要。可行的方向是:增加节点之间的额外空间关系(距离,角度,扭曲等信息)、添加非键合的边(非键合节点之间的空间接近性)、明确可学习子图之间的关系(官能团,环状结构的相对位置,功能等等)。
other graph
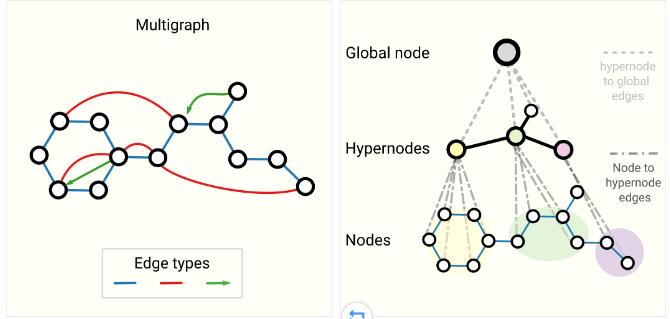
- 多图。图中一对节点可以共享多种类型的边,在社交网络中根据节点关系类型为不同的边设计不同类型的message passing方法。
- 嵌套图。如hypernode graph(超节点图),一个节点表示一个图,其在表示层次信息时非常有用,比如说在方程式反应图中,分子就使用节点表示。
- 超图。图中一个边可以连接多个节点。
sampling graph & batching
易知传统神经网络训练选用的mini-batch对图来说并不完全适用,因此GNN中的batch无法使用固定的批量大小。GNN中的batch要创建保留较大图形本质属性的子图,该种sampling高度依赖于具体的图特点。
如果想要在领域级别保持结构,一种方法是随机采样一组均匀分布的节点,即node-set。之后将距离为k的相邻节点和边添加至node-set中。每个邻域都是独立的图,并可以在GNN上进行训练。然而采样的原node-ser节点的邻居节点的邻域信息是不完整的,因此这部分的损失需要忽略。一种更有效的策略是首先随机采样一个节点,扩展其邻域到距离k,然后在扩展集中选择其他节点。这些操作可以在构建一定数量的节点、边或子图时终止。如果上下文允许,我们可以通过选择一个初始节点集,然后随机采样一个固定数量的节点,例如随机或通过random walk(随机游走)或Metropolis算法来构建恒定大小的邻域,即每次sample得到的子图大小一致。
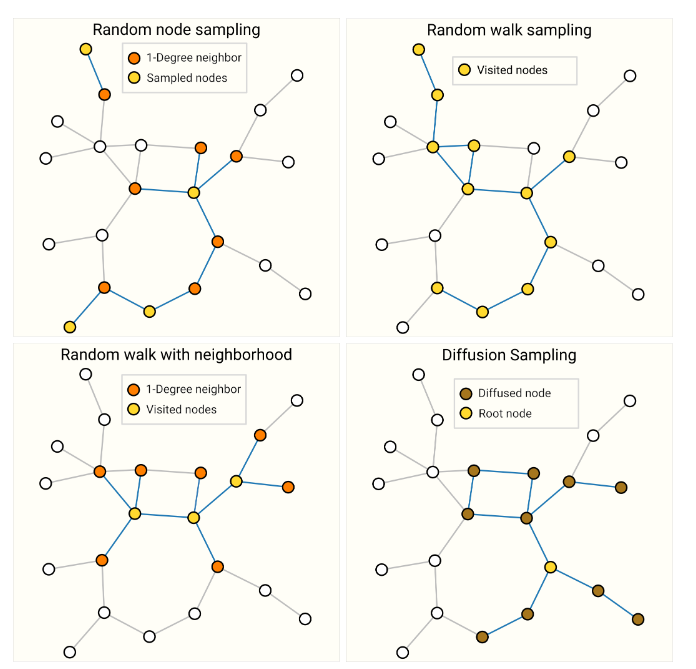
上图是四种sampling的实例,具体哪种策略的选择高度依赖上下文。另,对于高度链接的图,也可以对边采样。
当图大到难以放入内存,sampling就显得额外重要。
inductive bias 归纳偏好
在GNN中,我们关注图中不同属性的相互关系,因此我们希望模型具有特定的关系归纳偏置。具体来说,
- 将节点和边视为一个集合,关心他们的整体结构和相互关系而非具体顺序
- 应该具有置换不变性,对于节点和边的不同排列应该有相同的输出
- 能够处理可变节点和边的数据,而非预先确定输入的大小和顺序
aggregate operation
GNN中的aggregate需要是一种平滑的操作,以便能进行反向传播,并且由于节点的数量可变,aggregate操作需在节点排序和提供的节点数量变化时返回稳定的结果。
一些可选的:sum mean max,方差。可见其输出皆是与输入顺序无关的。
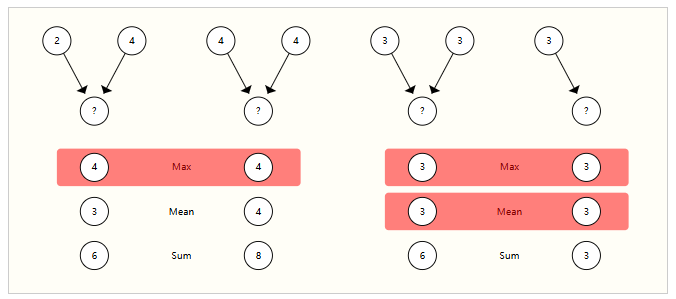
绝对地定义哪种operation更好是很难的,只能给出一般规律。当节点具有高度可变数量的邻居或需要规范化视图的局部邻域特征时,均值操作可能有用。如果想突出局部邻域中的单个显著特征时,最大值操作可能有用。求和在这两者之间提供了平衡,通过提供局部特征分布的快照,但由于它没有规范化,也可以突出异常值。在实践中,求和操作是常用的。
GCN
边和图的对偶
在图G上的边预测任务可以被表述为G的对偶图上的节点级预测。一个图及其对偶图包含相同的信息,只是以不同的方式表达。有时这种性质使得在一种表示中比在另一种表示中解决问题更容易。即若要在图G上解决边分类问题,可以考虑在G的对偶图上进行图卷积(这与在G上学习边表示是相同的)。可以参考这篇文章:Dual-Primal Graph Convolutional Networks。
矩阵与图
将一个邻接矩阵A与节点特征矩阵X相乘,就实现了一个简单的sum aggregate,内积恰恰能反映“求和聚合”,因为只有在A中的非零元素才会对聚合产生贡献。
而在邻接表中,操作更加简单——岂能直接忽略A的零元素进行aggregate,只需基于索引检索aggregate的条目即可。同样易知,aggregate的选择不只有sum。
值得一提的是,矩阵乘法可以看作是遍历图的一种形式,如邻接矩阵的二次幂能代表长度为2的路径点对,而且这种规律可以推广至n次幂。
GAT
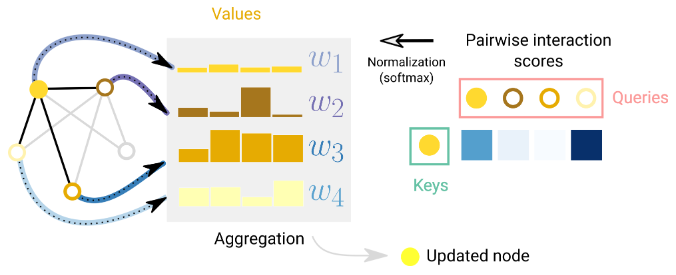
Graph Attention Networks(图注意力网络)是一种在图属性之间通过注意力机制传递信息的方法。例如考虑节点及其一度邻居节点的求和聚合时,可以考虑使用加权求和。
挑战在于,以一种置换不变的方式关联权重。一种方法是考虑一个标量评分函数,根据节点对(f(nodei, nodej))分配权重。在这种情况下,评分函数可以解释为衡量邻居节点在与中心节点相关任务中的相关性。权重可以通过softmax函数进行归一化,以便将大部分权重集中在与任务相关性最高的邻居节点上。这个概念是Graph Attention Networks(GAT)和Set Transformers的基础。
置换不变性得以保持,因为评分是基于节点对进行的。
常见的评分函数是将中间节点的查询向量和邻居节点的键向量内积(二者都通过学习得到),其能够反映对应节点的特征和相似性。内积的结果代表了注意力权重,从而影响后续的aggregate。权重也可以解释为便在特定任务中的重要性,即其对任务的贡献程度。
此外,Transformer也可以看作是具有注意力机制的图神经网络(GNN)。在这种视角下,Transformer将多个元素(如字符标记)建模为全连接图中的节点,并且注意力机制分配边嵌入到每对节点中,用于计算注意力权重。两者的区别在于它们假设实体之间的连接模式不同,GNN假设稀疏模式,而Transformer则对所有连接进行建模。
Explain & attributions
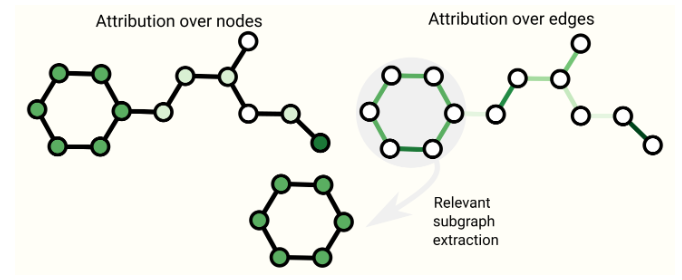
为了解释和理解GNN,提出了一些技术。
GNNExplainer方法试图提取对特定任务最重要的子图,从而揭示模型决策。
Attributions技术通过位图的不同部分分配重要性值来理解这些部分对任务的贡献程度。如下。
generative modling 图生成
生成模型从学习到的分布中进行采样,生成新的图,或是给定初始点完成图生成。图生成的难点是其拓扑结构复杂,一种可行的方法是仿照CV使用自动编码器框架来生成邻接矩阵。边的预测可以看作一个二分类任务(存在或不存在),同时预测时仅预测子集,从而降低复杂度。
grapgVAE(图变分编码器)专门用于学习如何模拟图的结构。它的任务是学习邻接矩阵中正连接模式(即已知存在的边)和一些非连接模式(即已知不存在的边或可能不存在的边)。通过这种学习,图VAE能够生成新的图或者完成给定图的重建任务,同时考虑到图的结构特征和连接模式的统计分布。