概述
《机器学习》周志华的读书笔记。
绪论
机器学习
机器学习是人工智能的一个子领域,旨在让机器学会自己完成某类任务。机器学习算法主要分为监督学习以及无监督学习。
监督学习
监督指为机器的学习提供算法实例,即输入x,和对应的输出,即正确解标签y,使得机器学习从x到y的映射。监督学习又根据任务不同,分为回归问题(预测)和分类问题。分类任务分为只涉及两个分类的二分类任务,和多分类任务。
无监督学习
无监督学习不提供正确解标签,旨在使算法发现数据的模式或规律。比如对未标记的数据放入不同的集群,即聚类算法,分入的不同集群称为簇;用于检测异常事件的异常检测算法;以及降维算法,其可以将大数据集进行压缩而尽量不丢失有用的数据。
数据
机器从数据中得到学习,学习过程中使用训练数据,测试过程中使用测试数据。机器学习旨在未见过的数据也能适用,称为泛化能力,一般而言,获得的样本数量越多就越容易得到强泛化的模型。然而,如果模型对训练数据学习的太好,将训练集的特质当作范式,会使得性能下降,即过拟合。相对的,欠拟合是指对训练样本的性质掌握欠佳。
假设空间
从数据中学习与推理思想中的归纳(从个别到一般)是类似的,因此也成为归纳学习。学习的过程就是在所有假设的空间中找到与训练集匹配的假设。获得的假设空间通常是不唯一的,选择某个合适的模型称为归纳偏好。神奇的是,在所有问题出现的机会相同时,基于归纳偏好选择的算法被证明在性能上是等价的(NFL定理),即脱离具体问题选择更好的算法毫无意义,也就是说,讨论算法优劣必须针对特定的问题。
模型评估
由于过拟合的问题存在,我们无法是用训练集评估模型的性能,因此我们使用测试集进行评估。因此,我们将数据集进行划分。
数据集划分
- 留出法。留出法直接对数据集进行拆分,同时保证样本的(不同类)比例相同。值得注意的是,不同的划分会导致模型结果的差异,因此需要若干次随机划分取均值。问题是,训练集越多,训练的越好,但评估不够准确,测试集越多,训练又不完整,这是个难以解决的问题。常见的划分比例为2:1至4:1。
- 交叉验证法。交叉验证法将数据划分为k个大小近似的互斥子集,进行k次训练,每次训练选取一个子集作为测试集,其他子集作为训练集。与留出法类似,要选择不同的划分方法重复p次取均值,称p次k折交叉验证。若k等于总数据量,则称留一法。
- 自助法。如果数据及大小为m,该方法放回的抽取m次数据作为训练集,按照如下概率公式可知,约有36.8%的数据不会出现在训练集,将其作为测试集。
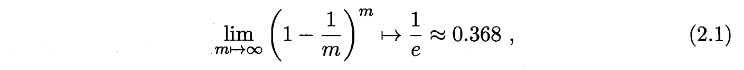
- 调参。参数配置不同也会导致模型性能的差异。我们将训练集在划分为训练集和验证集,验证集用来进行模型的调参。
性能指标
介绍一些概念:
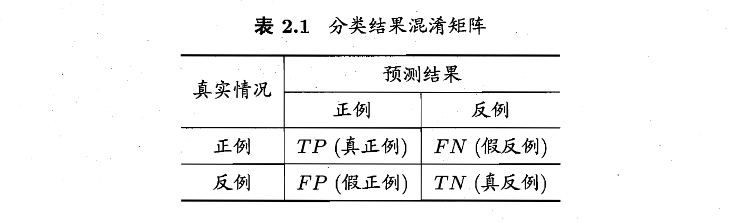
有如下指标:准确率,召回率,F1,$F_\beta$,micro,marco;TPR,FPR,ROC,AUC。不再赘述。
此外,实际任务中,FN和FP的错误等级往往不同,我们引入代价矩阵来表示不同的损失,以二分类为例。
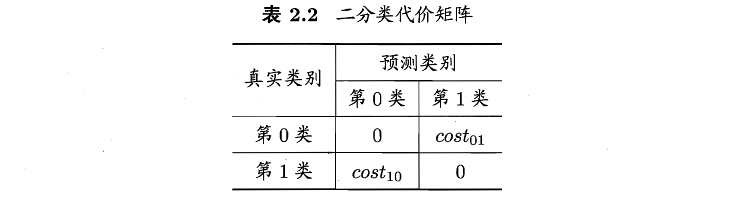
相应的,会有代价曲线。其可反应学习的期望总体代价。
比较检验
我们借助统计假设检验来判断,如果在测试集上观察学习器a优于b,则a的泛化性能是否在统计意义上优于b,以及这个结论的把握有多大。很容易联想至概率统计中假设检验的概念。
假设检验
我们根据测试错误率估推出泛化错误率的分布,泛化错误率为e的学习器被测得测试错误率为e‘的概率为
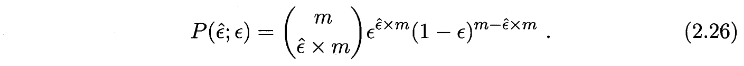
已知测试错误率,可见p在e=e’时最大,这与二项分布一致。我们使用二项检验计算假设在显著率$\alpha$下的置信区间。
多次留出法。