[toc]
概述
读书笔记,鱼书三件套的第二本,NLP基础。相关电子版书籍请见。
本书在上一本《深度学习基础》基础之上拓展了介绍了自然语言处理的相关知识,主要涉及word2vec、RNN、seq2seq、Attention的基本概念。
语言和表示
日常交流使用的中文,即自然语言(natural language)。 所谓自然语言处理(Natural Language Processing,NLP)是处理自然语言的科学。即,让计算机理解人话。
理解语言的基础是理解单词。
基于同义词词典的方法
在同义词词典中,具有相同含义的单词(同义词)或含义类似的单词(近义词)被归 类到同一个组中。也会定义单词之间的粒度更细的关系,比如“上位-下位”关系、“整体-部分”关系。如下
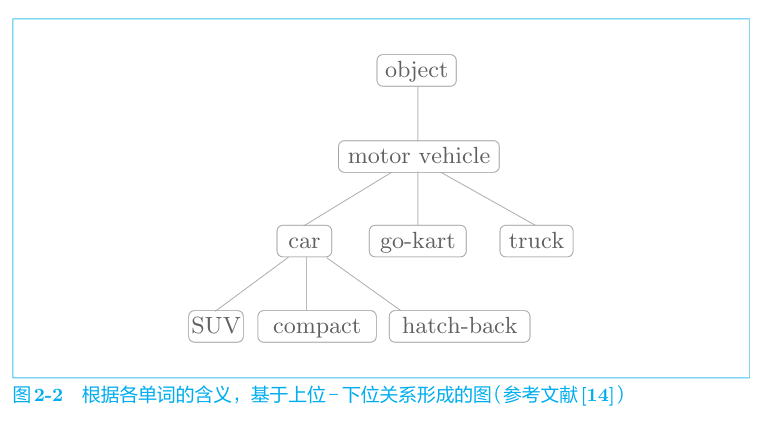
然而同义词词典的问题也很明显
- 时代在发展,会有新单词,单词会有新含义,需要人工不停地更新同义词词典。
- 需要巨大的人力成本。
- 含义相近的单词,也有细微的差别。其在词典中无法体现。
基于计数的方法
本节中将使用语料库,即大量的文本数据。
预处理
首先,对语料库进行分词,并对单词进行id编号,用字典保存。
1 | 分词中可以使用正则表达式 |
例如对于一个text字段,我们使用preprocecss对其进行处理

获得单词id列表

以及id和单词的对应表

单词表示
其次,将单词通过某种方法表示为向量,即单词的分布式表示。
其实相比于CV领域中图片的像素点可以很轻松的使用RGB表示,NLP很难找到一个类似的桥梁。
因此,我们引入这样的假设——某个单词的含义由它周围的单词形成,即分布式假设。周围的单词称为上下文。上下文的大小称为窗口大小。
1 | 窗口大小为1,则仅关注左右各一个单词。 |
对上述的例子,我们假设窗口为1,统计各单词周围的单词频数,用矩阵表示如下。

上述矩阵称为共现矩阵,其各行即相应单词的向量。
单词的相似度可以通过向量的余弦相似度比较,对于x,y向量,其相似度定义为
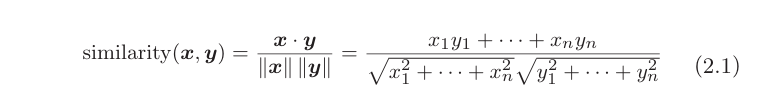
基于计数的方法改进
之前的共现阵表示了单词共同出现的次数。但是多次出现的冠词“the“,”a”,会导致“the car”的出现频率远高于“drive car”,即前者相关性强于后者。显而易见,正确结论是相反的。
我们引入点互信息,(Pointwise Mutual Information, PMI)。对于随机变量x和y,它们的PMI定义如下,,P(x)表示x发生的概率,P(y)表示y发生的概率,P(x,y)表示x 和y同时发生的概率。PMI的值越高,表明相关性越强。
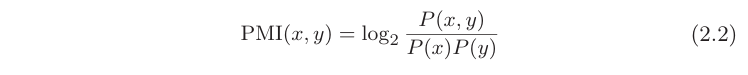
NLP中。概率即单词出现的次数C(x),C(y)。即
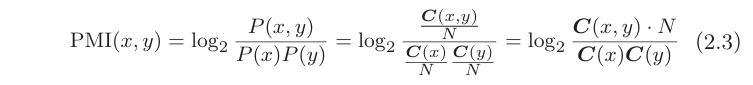
PMI的值在x,y共现次数为0时不收敛。我们将其改进为PPMI(Positive PMI)
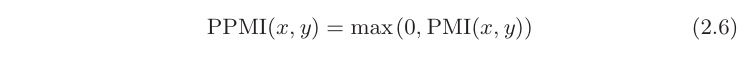
通过计算,之前的共现矩阵变成了PPMI矩阵

PPMI矩阵仍存在问题。其行列长度都是单词个数,如果语料库词汇很大,那空间复杂度难以想象。我们观察到向量是稀疏的,即,仅有少量元素非零。我们尝试减少向量的维度,即降维——在稀疏向量中找出新的轴,用更少的维度将其进行表示,从而使得其变为密集向量。我们借助奇异值分解SVD,SVD 将任意矩阵分解为3个矩阵的乘积。
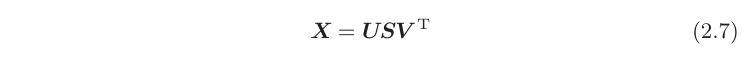
其中U和V是列向量彼此正交的正交矩阵,S是除了对角线元素以 外其余元素均为0的对角矩阵。即
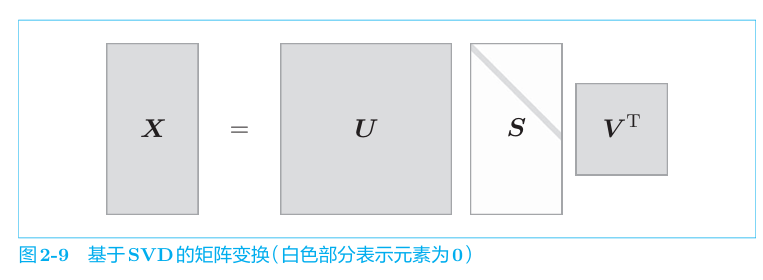
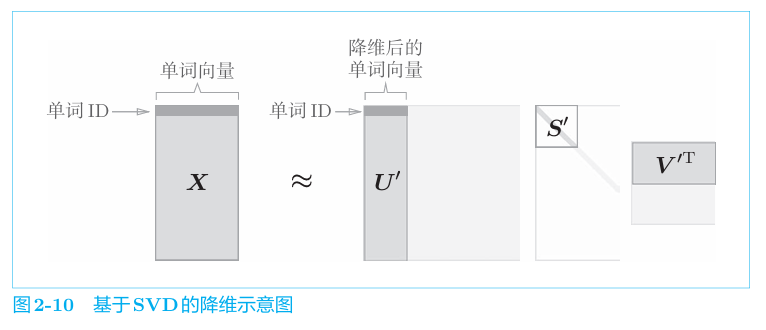
最终获得了降维后的单词表示。
word2vector
概述
在数据库预料数量很大时,基于计数的方法有很高的时间复杂度。
1 | 如SVD在处理n X n矩阵时的时间复杂度是O(n^3) |
本章介绍是用神经网络的方法,即基于推理的方法。相比于基于计数的方法处理全部数据,基于推理的方法能够使用minibatch进行学习,从而加速整个过程。
比较违反直觉的是,基于推理的方法的期待输出并不是单词的分布式表示,而是要根据上下文正确预测句子某位置的单词是什么,如下所示。(也就是说,单词的表示只是学习过程“中间”的产物)

在整个训练过程中,采用独热(one-hot)编码将单词转化为固定长度的向量。例如“You say goodbye and I say hello.”的文本,每个单词使用id的onehot表示。
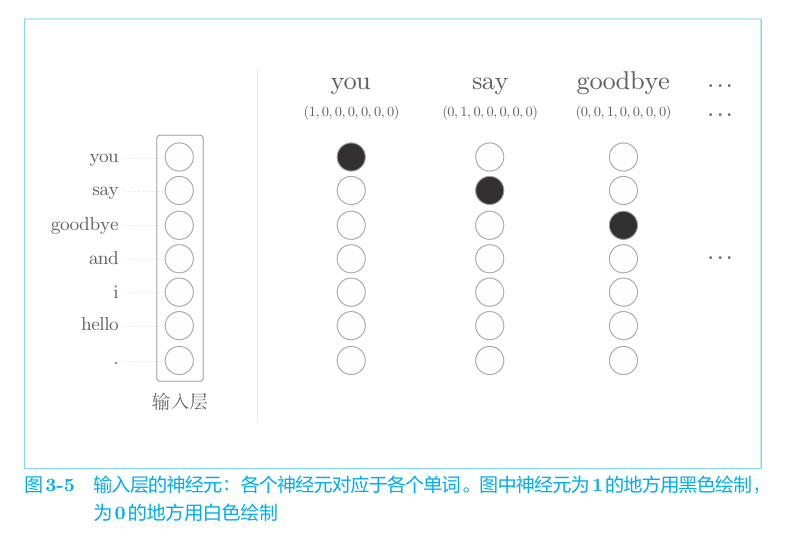
对应的向量构成网络的输入层。
CBOW连续词袋模型
1 | 原版word2vector提出的continuous bag-of-words模型。即CBOW |
模型结构
如下
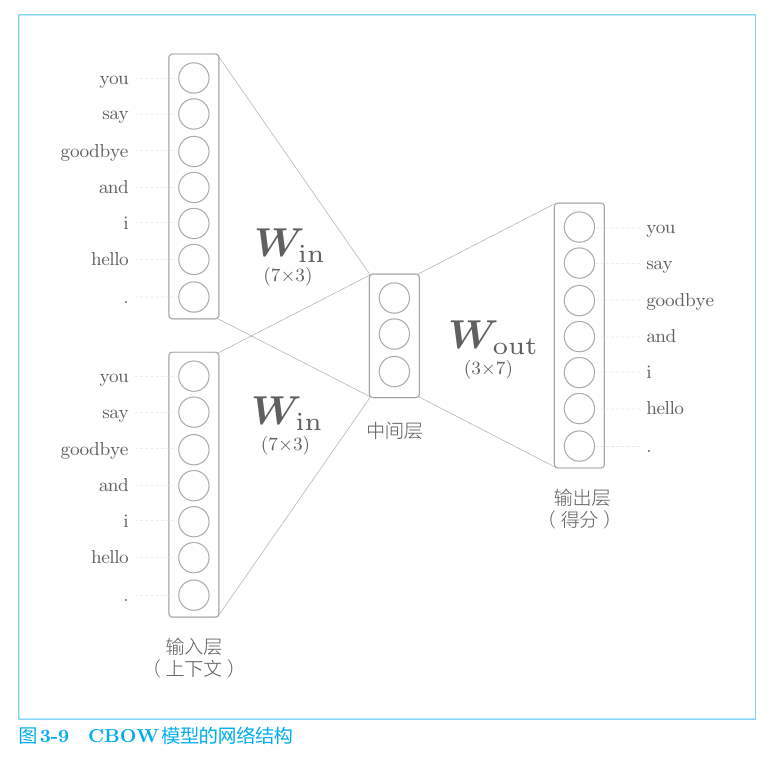
模型有两个输入层,输入到中间层通过相同的全连接层,中间层到输出层通过另一个全连接层。中间层是两个输入层变换后的平均。输出层的七个神经元对应各单词,代表其得分。得分越大,则概率越高。
1 | CBOW仅考虑2个上下文,故需要2个输入层。考虑N个单词需要N个输入层。 |
在神经网络的学习中,权重不断地调整,矩阵各行不断更新,从而根据上下文成功预测单词;最后,输入权重矩阵的每行就对应这各个单词的分布式表示。如下。
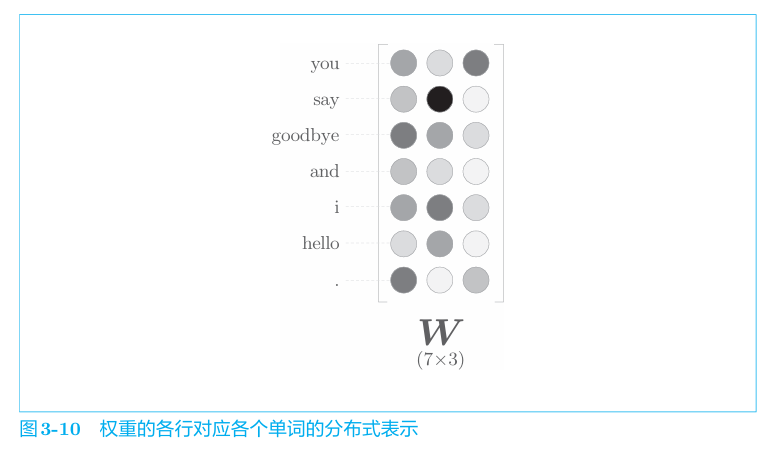
1 | 同样,输出层的权重矩阵每列都是单词的编码向量,只不过就CBOW而言,其只使用了输入层的权重矩阵。 |
数据准备
模型对输入的上下文,使得目标此的出现概率最高。从语料库中(仍以之前句子示范)获得数据。

具体来说通过id来实现。
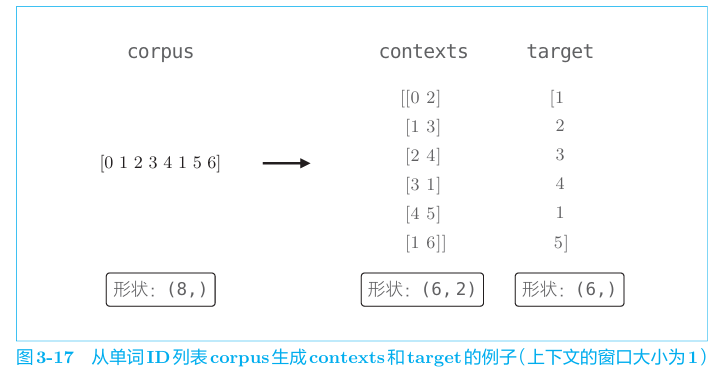
把他们转成one-hot向量

模型的学习
由上下文预测单词,即多分类任务。使用softmaxwithloss。
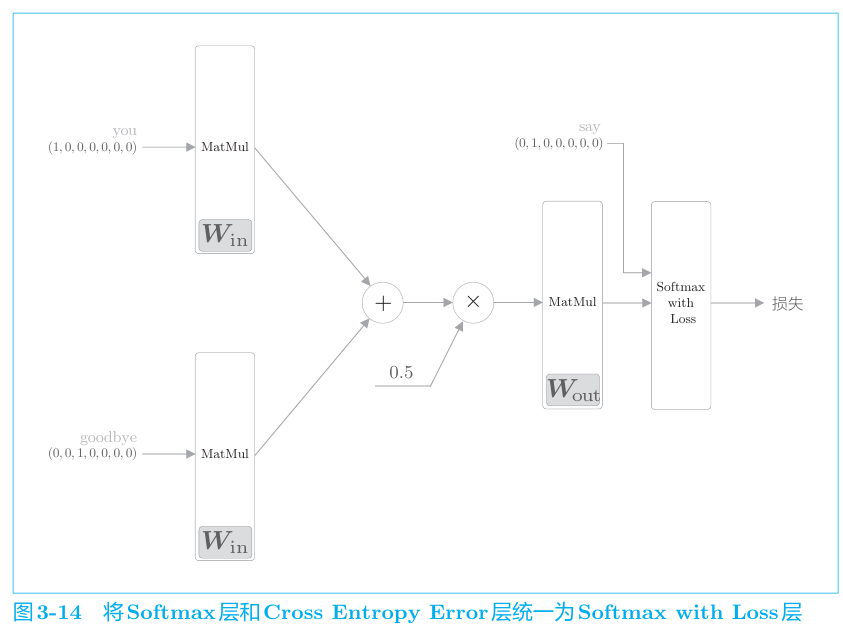
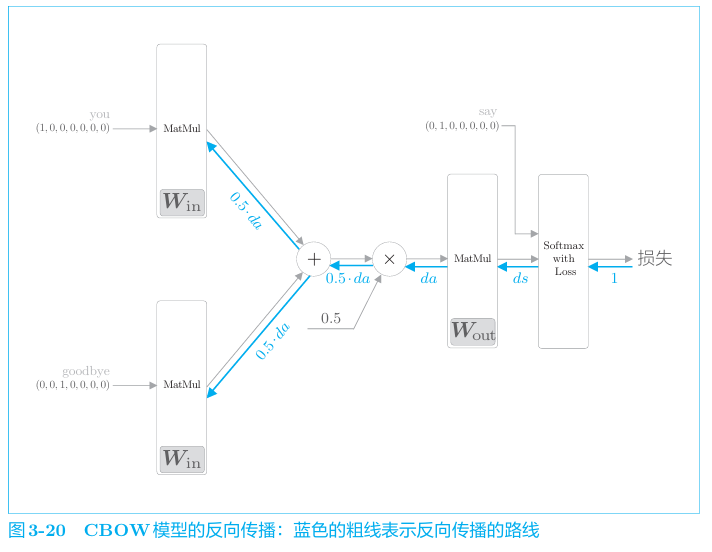
对应的反向传播。
skip-gram模型
skip-gram模型则从中间的单词(目标词)预测周围的多个单词,即
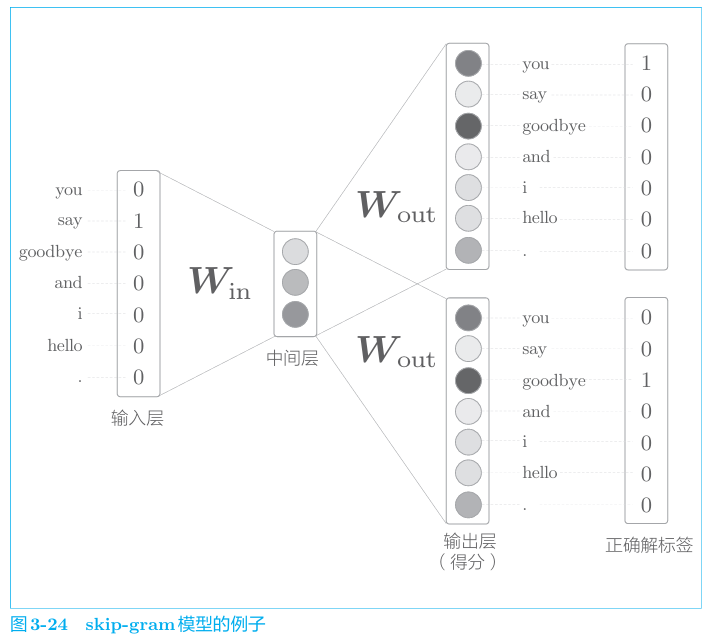
1 | 在大多数情况下,skip-grm模型的结果更好。原因是:相比于给出you、goodbye来预测say,给出say来预测you、goodbye更难,这使得模型获得更完好地表示。 |
几点说明
- 基于统计和基于推理的方法都能获得单词的的相似性表示,二者的优劣度被证明是相近的。
- 基于推理的方法还能理解单词之间更复杂的模式,请见。
- 这两个方法其实在某程度上是互通的。
- Glove方法结合了二者,请见。
word2vector的高速化
CBOW模型在处理大型语料库时速度很慢,本章将专注于加速word2vector。
Embedding
CBOW中,token使用one hot表示,其组成的矩阵与W_in进行相乘运算。one hot向量的维数即总token的个数。如果token很多,计算复杂度很高。
但其实one hot表示进行矩阵乘法相当于取出某一行。我们根据这个思路来简化运算。
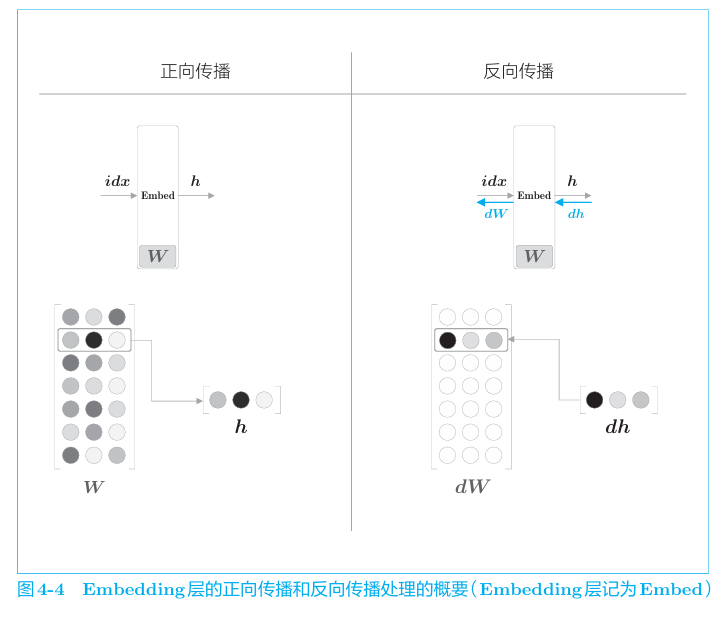
我们把从参数矩阵中抽取行向量的层称为embeding层,其实现非常简单,取特定索引的行即可。用其替换CBOW中的Matmal层即可。
1 | embeding即嵌入,和之前的分布式表示异名同义 |
对应的前向、反向传播如下
如上我们简化了输入侧的运算,接下来简化输出侧。
先说一点题外话——给定上下文预测“?”token的任务可以看作一个多分类任务,即从很多token中选择正确的“?”token。我们把这个问题简化为二分类任务,即对每个token判断其是不是“?”token。
这样CBOW模型改进如下
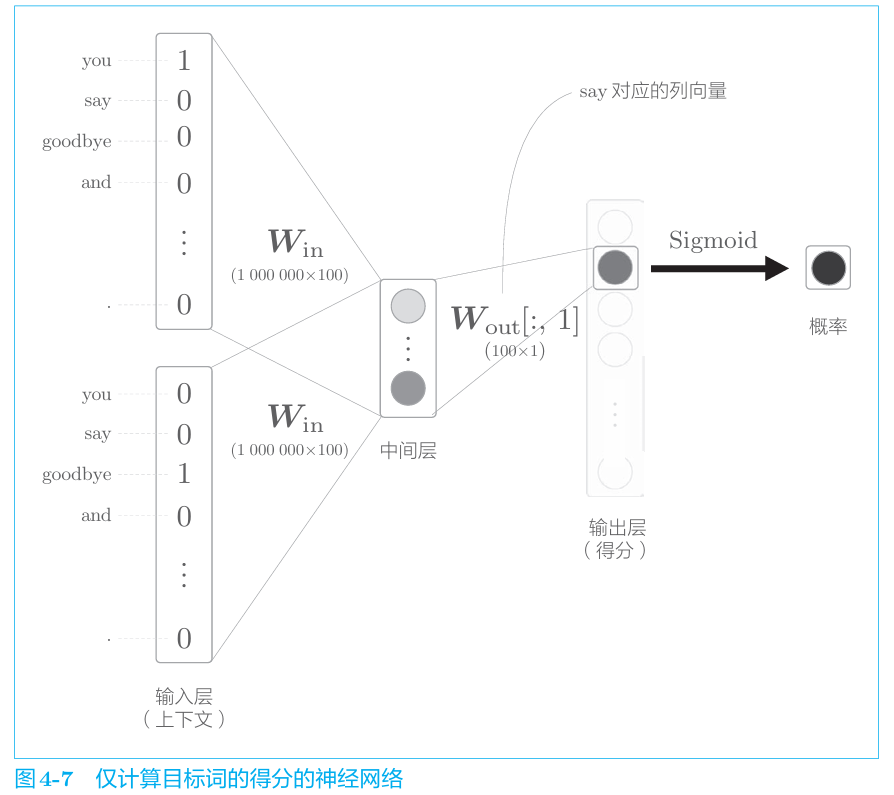
我们发现输出层的行向量维度从token数量变成了1,这样在计算中间层与w_out矩阵的乘积就变成了对应行与列向量的点乘。即
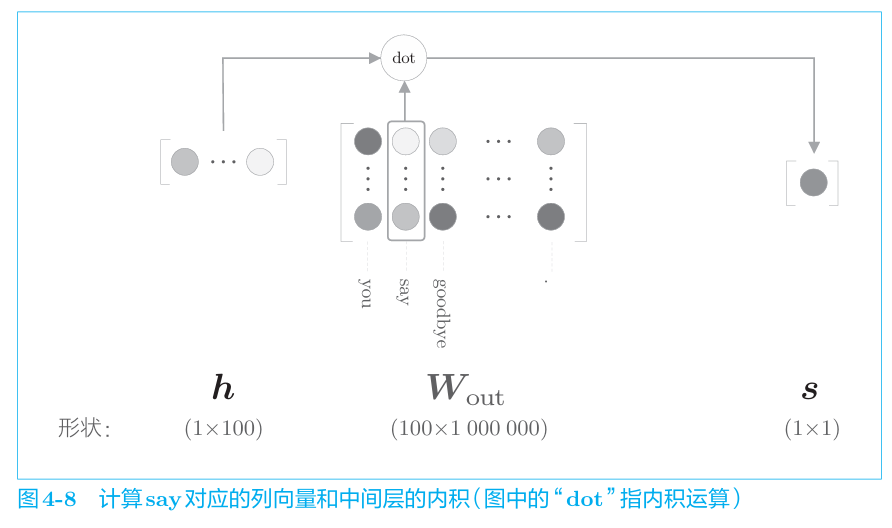
在多分类任务中,使用softmax进行概率转换,二分类则使用sigmoid函数进行概率转化。二者相同的是都是用交叉熵误差。
sigmoid函数之前已经介绍过,不再赘述。
经过上述简化得到的神经网络如下所示。
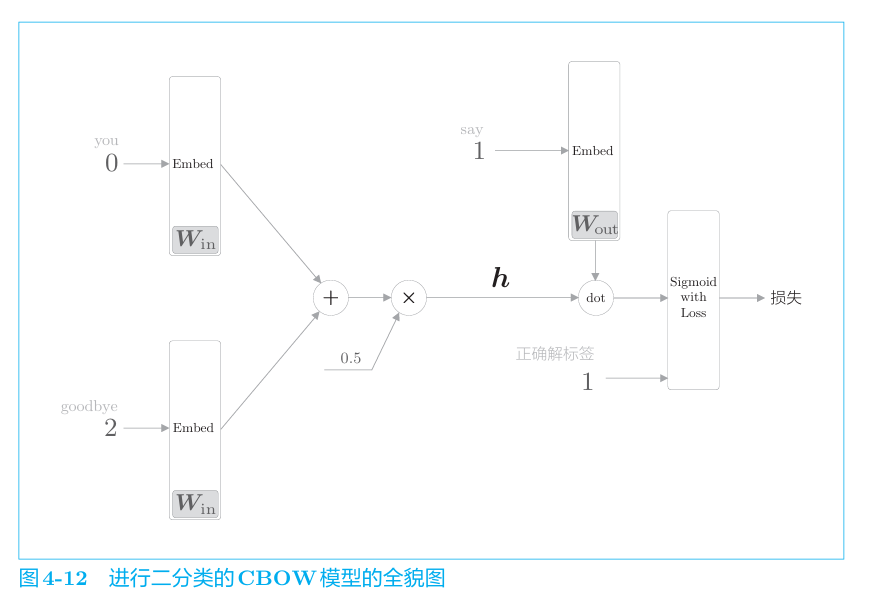
负采样
我们通过把多分类转化为二分类,问题得到了简化,但是问题是,模型仅仅学习到了正例,而没有学到负例。即,对模型输入you和goodbye,目标say的的概率要接近1,输入say以外的单词,概率要接近0。如下。
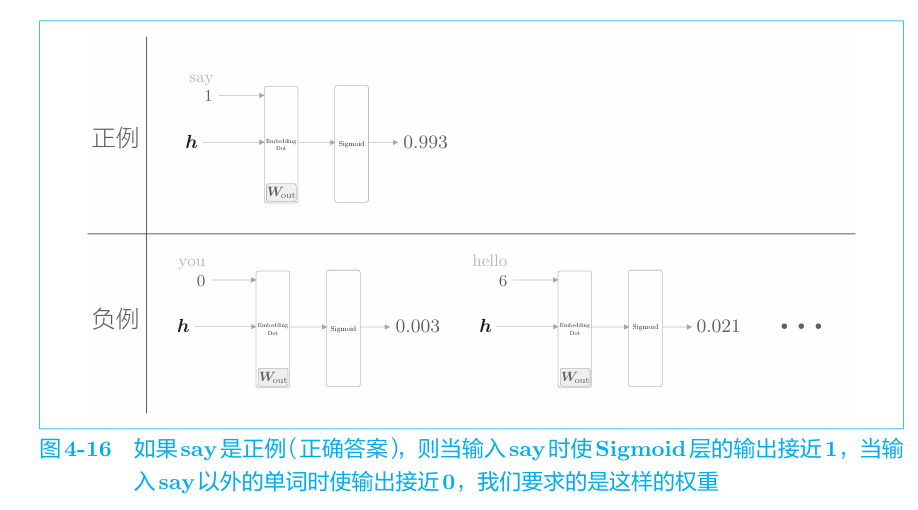
若要选择所有负例进行学习,则之前的优化也就无意义了,因此我们选择特定的负例,将这些数据(正例 和采样出来的负例)的损失加起来,将其结果作为最终的损失。
结合前例来说明。假设选取2个负例目标词hello和i,则负采样的计算图如图所示。
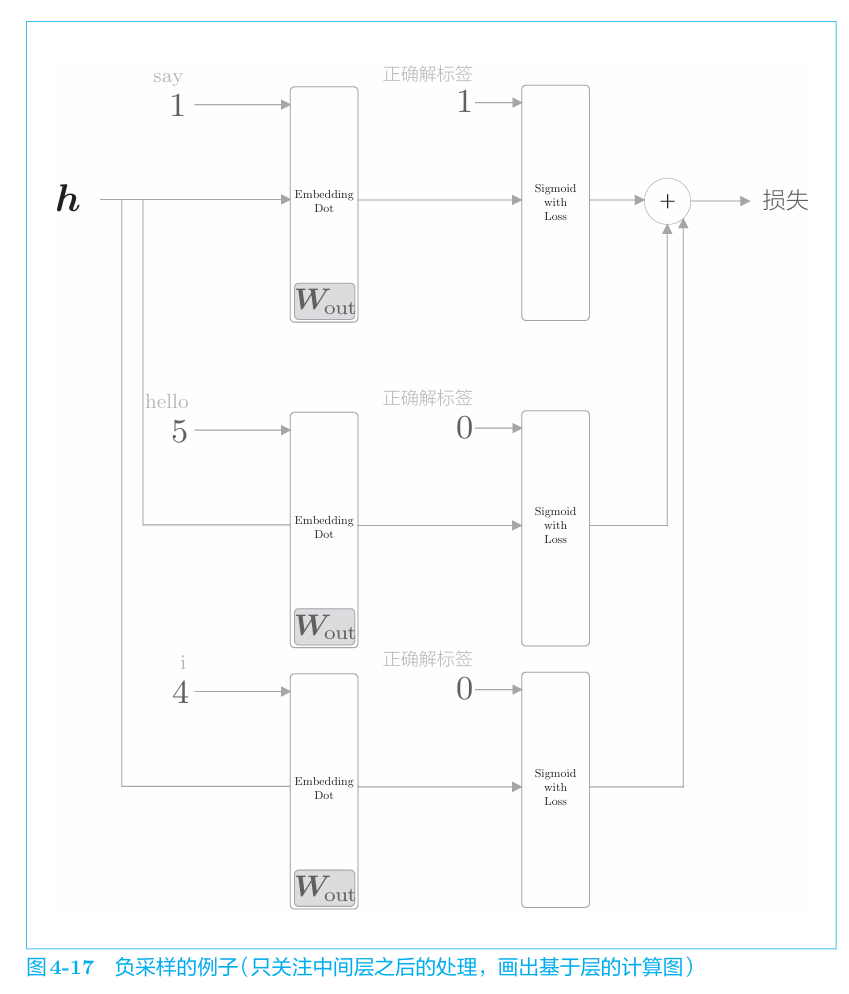
1 | 我们在选择负例时,可以参考语料库,使经常出现的单词容易被抽到。 |
RNN
语言模型LM
语言模型(language model)给出单词序列发生的概率。即,使用概率评估一个单词序列发生的可能性,即在多大程度上是自然的单词序列。
1 | 比如,对于“you say goodbye”这一单词序列,语言模型给出 高概率(比如0.092);对于“you say good die”这一单词序列,模型则给 出低概率(比如0.000 000 000 003 2) |
如果对概率论熟悉,m个单词的句子概率为。

考虑使用之前的CBOW模型,调整其窗口大小即可获得概率。比如说将窗口调整为左侧2个单词右侧0个,对应的的句子概率为。
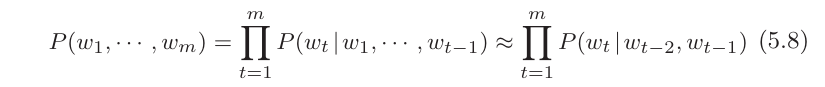
然而CBOW有如下的问题
- 窗口太小无法记住长距离的信息,太大又增加运算。
- CBOW的输入是无序的,you say和say you会被看做相同的输入
RNN
RNN(Recurrent Neural Network)循环神经网络便登场了。其可以处理任意长度的序列。
结构
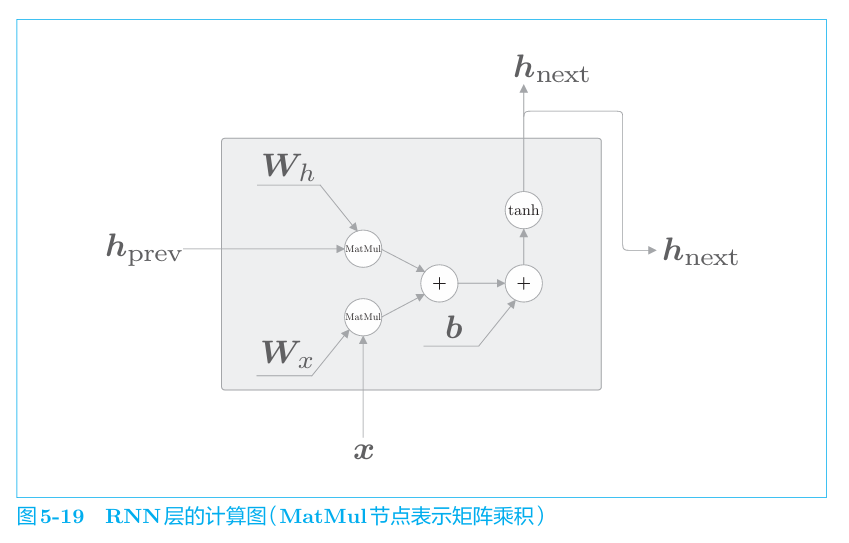
RNN层如下
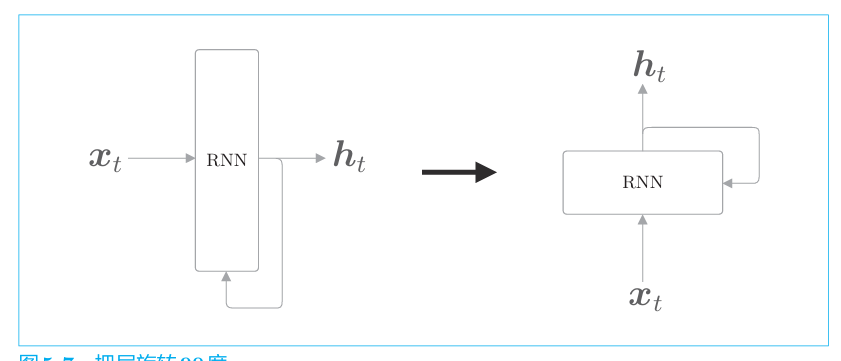
xt是向量。比如t时刻单词的分布式表示。
1 | 在RNN中,时序数据是按时间顺序排列的,时序数据的“时刻”与普通数据的“索引”同义。NLP中,时刻为t的单词也就是第t个单词。 |
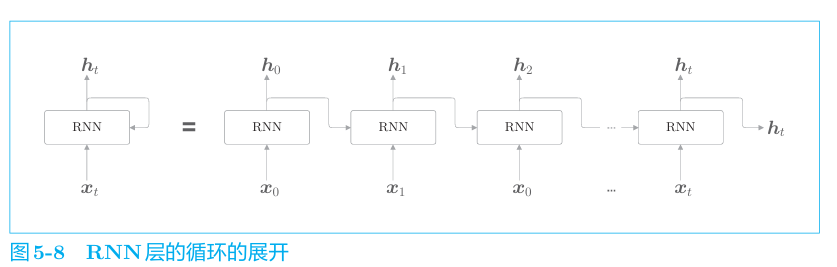
通过展开RNN层的循环,将其转化为了从左向右 延伸的长神经网络。这和之前的前馈神经网络的结构相同。不过,图中的多个RNN层都是“同一个层”,这一点与之前的神经网络是不一样的。
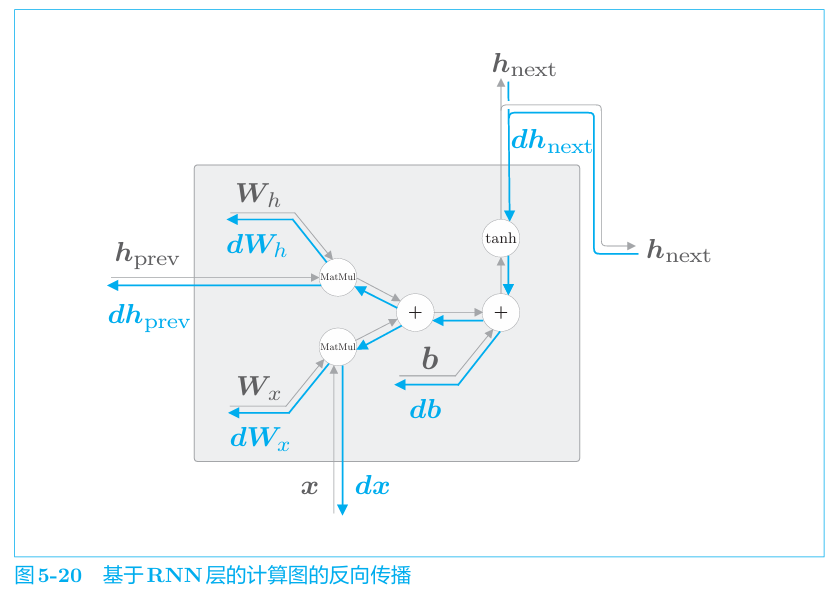
每个RNN层中的输出h_t计算如下。
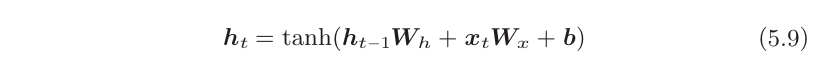
RNN有两个权重,分别是将输入x 转化为输出h的权重W_x和将前一个RNN层的输出转化为当前时刻的输出的权重W_h。此外,还有偏置b。
1 | ht称为隐藏状态(hidden state)或 隐藏状态向量(hidden state vector) |
反向传播
展开后的RNN与传统的前馈神经网络结构相同,其正向,反向传播如下
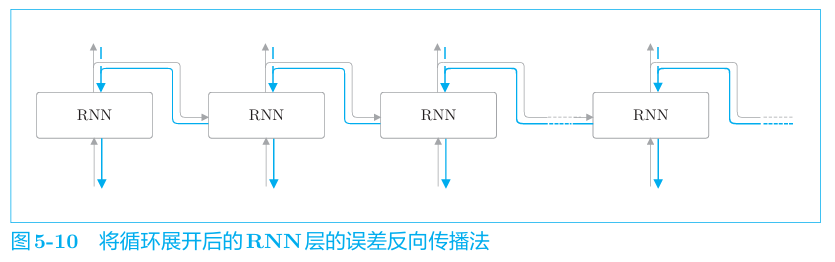
因为这里的误差反向传播法是“按时间顺序展开的神经网络的误差 反向传播法”,所以称为Backpropagation Through Time(基于时间的反向传播),简称BPTT。
在处理长时序数据时,通常的做法是将网络连接截成适当的长度。具 体来说,就是将时间轴方向上过长的网络在合适的位置进行截断,从而创建 多个小型网络,然后对截出来的小型网络执行误差反向传播法,这个方法称 为Truncated BPTT(截断的BPTT)。只是网络的 反向传播的连接被截断,正向传播的连接依然被维持,例如
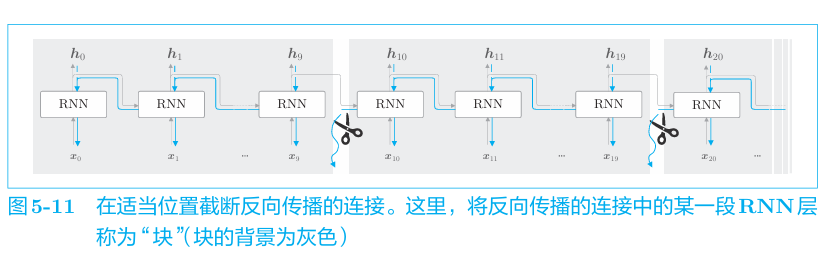
即
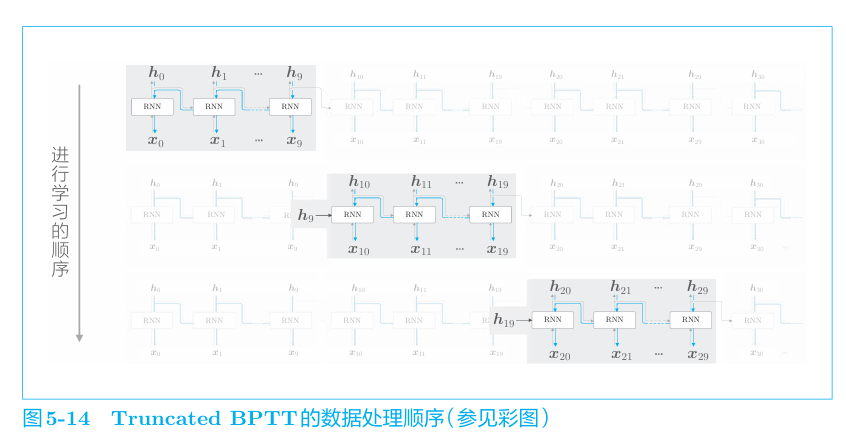
通过将数据按顺序输入,从而继承隐 藏状态进行学习。
minibatch
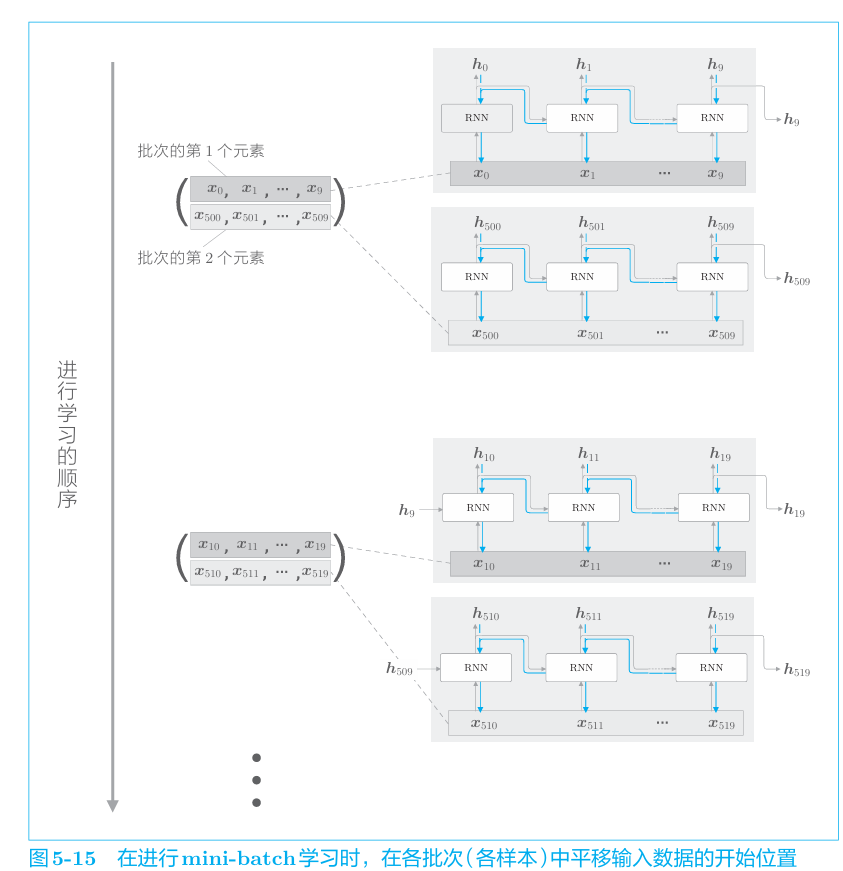
我们之前的探讨对应于批大小为1的情况。为了执行mini-batch 学习,需要考虑批数据,让它也能像图5-14一样按顺序输入数据。因此,在输入数据的开始位置,需要在各个批次中进行“偏移”。
仍用上一节的通过Truncated BPTT进行学习 的例子,对长度为1000的时序数据,以时间长度10为单位进行截断。此时, 如何将批大小设为2进行学习呢?在这种情况下,作为RNN层的输入数据, 第1笔样本数据从头开始按顺序输入,第2笔数据从第500个数据开始按顺 序输入。也就是说,将开始位置平移500,如图
正向传播
反向传播