论文阅读,用于NER的PIQN框架。原文,来自ACL 2022。
概述
本文提出了一种并行实体查询框架,查询作为可以训练的向量并行提取实体。
模型结构
输入
输入由两部分组成,一个是n个单词组成的句子序列,其中实体使用首尾指针标记。以及m个查询组成的查询序列,每个查询提取一个实体。
我们将两个序列进行token,position,type嵌入。嵌入向量长为h。三部分相加作为输入。
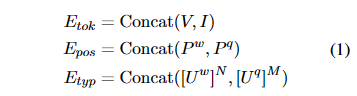
1 | type嵌入需要将标签重复n次,来对齐长度。 |
本文修改了传统Attention矩阵,从而隔离查询(随机初始化的)和句子的语义交互。
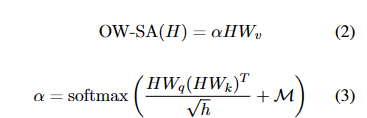
引入了一个掩码矩阵,右上子矩阵值为-inf,其余为0。
1 | 查询可以相互注意,以增强语义。 |
Encoder后,再通过两个bilstm和l额外的变换器层,得到句子编码和查询编码。
预测
实体查询看作是位置和类别的联合任务。
位置预测通过预测实体的首尾指针实现。

得到了一个融合表示(向量)。
计算句子的第 j 个单词是左边界或右边界的概率:
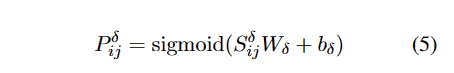
其中$\delta$为l or r,代表左右指针。最后所有组合中概率最大对应的单词即左右指针。
类别预测
第 i 个实例查询的边界感知表示可以计算为:
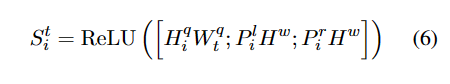
属于类别 c 的第 i 个实例查询查询的实体的概率:
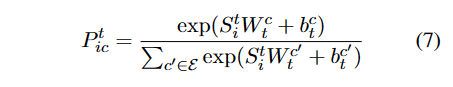
概率最大的标签c为最终类别。
LAP
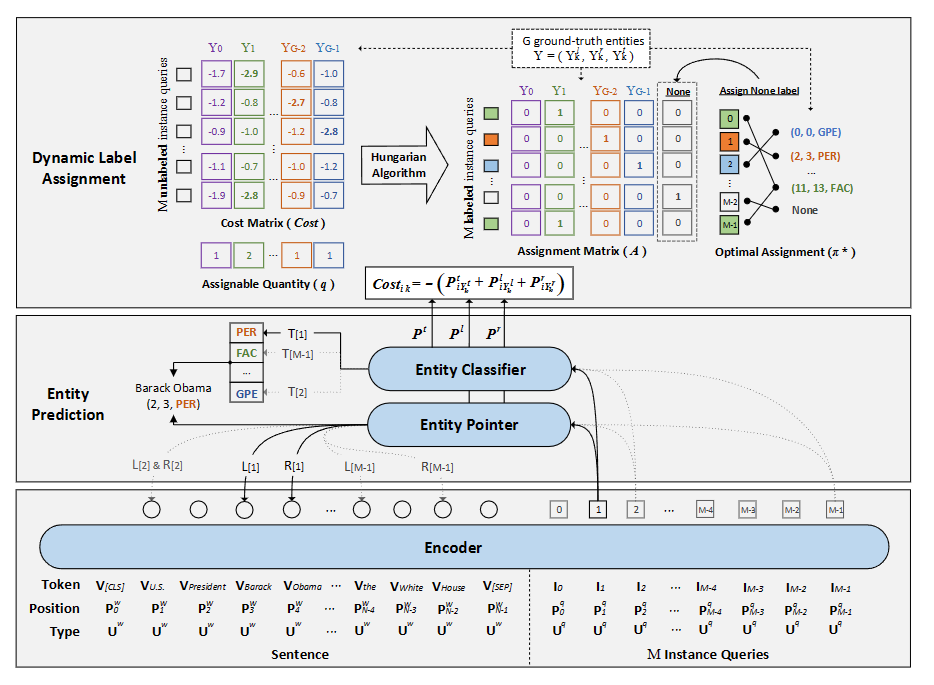
因为查询是隐式的,我们不能提前分配训练标签。因此在训练时动态分配标签。
假设第k个实体分配个第i个查询的成本定义为
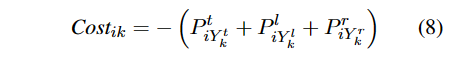
分配时使得总成本最小
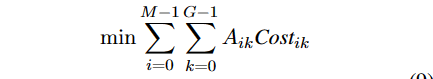
A是分配矩阵,若第k个实体分配个第i个查询,则Aik=1。
1 | 通过匈牙利算法得到这个矩阵。见附1。 |
问题是查询数量大于可分配实体数量,在矩阵最右扩展一列,列向量的元素满足
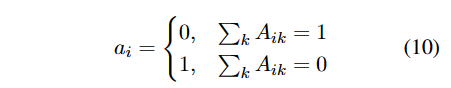
这样没有被分配到实体的查询也可以采用统一的表示,即第i行的最后一列为1。
每一行中找到元素为1的列索引,即实体标签的索引,将这些索引组成一个向量。这样便完成了查询与实体的匹配。
loss
对于左右边界预测,使用二元交叉熵损失函数。
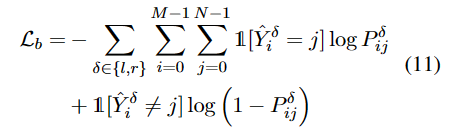
对于实体分类,我们使用交叉熵函数。
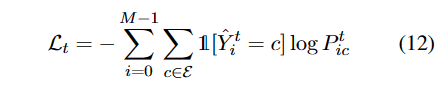
看起来重影的1是一种函数,其在中括号内的语句为真时取1,反之取0。
在每个Transformer后面都添加二者的预测,得到两个损失,训练集D上的总损失为。
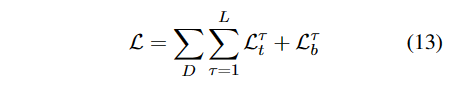
1 | 预测时只在最后一层预测。 |
实验
略。