论文阅读,原文。来自ACL 2020。
概述
提出了一个处理嵌套NER和平面NER的统一框架,将NER处理为机器阅读理解任务(MRC)。而非序列标注问题。每个实体通过自然语言的形式查询,比如PERSON的标签分配通过回答“文本中提到了谁”的问题来实现。
可见相比序列标注问题,其可以解决嵌套实体问题。除此之外,序列标注只是标签的简单索引,并没有任何语义信息,而MRC问题中提供了关于实体类别的详细描述等先验信息。
1 | 例如,查询“在上下文中查找公司、机构和单位等组织”不仅告诉模型需要查找“组织”类型的实体,还提供了“公司、机构和单位”这些具体的例子。 |
模型
输入
我们将带有标记的数据集转化为(question,answer,context)三元组。每个标签类型关联到一个自然语言问题,即question。一个标注的实体是一个连续的字符片段,即answer。实体所在的输入序列 X 即context。
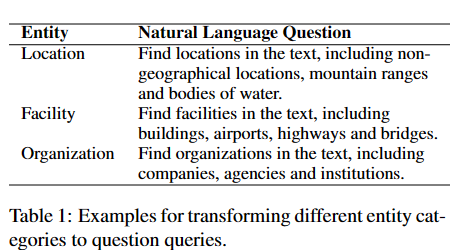
question的设定参考了标注指南笔记,其常用来给予人工标注者数据指导,如下。
MRC使用采用BERT,将问题q_y和序列x拼接(即充当BERT中的句子A,B)组成token序列,{[CLS], q1, q2, …, qm, [SEP], x1, x2, …, xn},其经过BERT得到上下文表示矩阵E_n*d,可以看到我们忽略了question的嵌入。
跨度的选择
我们使用两个二元分类器,一个预测token是否为起始索引,一个预测token是否为结束索引。
1 | 另一种可用的方法是采用两个n类分类器,即在n个token中选择是“起始,结束”类别的token。 |
由嵌入矩阵E,每个标记作为起始索引的概率为
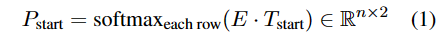
T是要学习的参数,
结束索引同理,将start更改为end即可。
索引匹配
每个question会对应很多实体,因此起始终止索引也不唯一,如何将同属一个实体的索引匹配呢?
我们找到所有可能是起始索引和终止索引的集合。
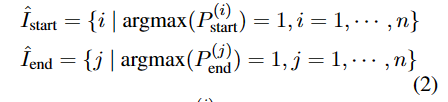
对于集合的任意始终索引对,训练二e分类模型预测其是否匹配
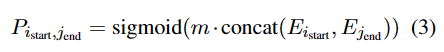
m是要学习的参数。
训练及测试
训练时,X与长为n的两个标签序列Ystrart,Yend配对,对于索引的预测,使用交叉熵损失(CE)。
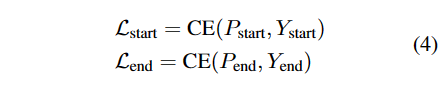
索引匹配的损失为

总体loss
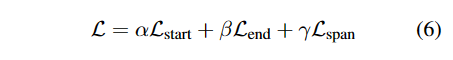
$\alpha$等是设定的超参数,依规定各部分对总loss的贡献。三个loss端到端的方式联合训练,并在bert共享参数,即使用相同的bert嵌入。
测试时,集合中选择对应索引组合,输入匹配模型最终得到答案。
实验
略。