读论文,连续空间词表示的语言规律,原文。来自 NAACL 2013。
概述
本论文展示了通过训练神经网络模型获得的连续空间中的词表示(也就是进行word2vector)能够捕捉到一些有趣的语言规律。并且关系也可以通过特定的向量偏移来表征(例如king-man+woman对应的向量与queen的向量接近),这使得基于词向量偏移的向量推理成为可能。具体来讲,通过句法类比问题展示了word2vector捕捉句法规律的能力,通过向量偏移方法展示了word2vector捕捉语义规律方面的能力。
RNN
关于RNN不再赘述,可以参考这里。
句法类比
本文新建了一个数据集,用于类比问题测试,形式类似“a to b as c to ?”。囊括了形容词的原型比较级最高级,单词单数复数,名词所有格非所有格。
语义规律
使用SemEval-2012 task2评估关系相似度。例如,对于 ClassInclusion:Singular Collective 关系,典型的词对是 clothing:shirt。为了测量目标词对 dish:bowl 是否具有相同关系的程度,我们形成类比 “clothing 相对于 shirt 就像 dish 相对于 bowl”,并评估其有效性。
向量偏移方法
如上,句法与语义都被表述为类比问题。要回答类比问题 a:b as c:(d?)(其中 d 是未知的),我们找到嵌入向量 x_a, x_b, x_c(都归一化为单位范数),并计算 y=xb−xa+xc。 y是我们期望的最佳答案的连续空间表示。当然,可能没有单词正好位于该位置,因此我们接下来搜索与 y 具有最大余弦相似度的单词,并输出它。
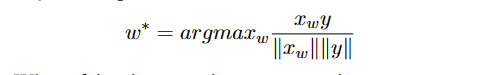
实验
相比于其他方法,RNNLM确实在数据集上表现最好。即可以捕获到相应的规律。