论文笔记2,ALBERT,原文。 来自ICLR 2020。
概述
在BERT中,预训练阶段增加模型大小会增加下游任务的性能,但是会带来算力的增加。ALBERT就是基于降低BERT的内存损耗和训练时间而设计的,即Lite Bert。具体来说,ALBERT结合了两种参数缩减技术,一是分解嵌入参数化,二是跨层参数共享。同时还引入了句子顺序预测SOP。
架构
ALBERT的架构设置与BERT类似,词汇嵌入大小表示为 E,编码器层的数量表示为 L,隐藏大小表示为 H。feedfoward大小4H,注意力头H/64。
下图是二者超参数之间的差异。
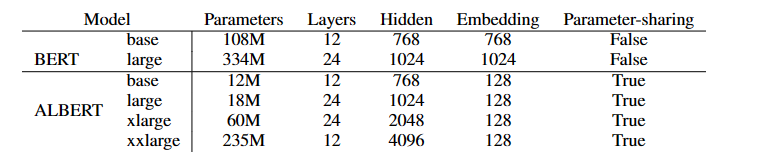
ALBERT相比于BERT的三种改进如下。
分解嵌入参数化(Factorized embedding parameterization)
在传统BERT以及变体XLNet,Roberta中,嵌入大小E == 隐藏层大小H。这是合理的吗?
- 词嵌入旨在学习与上下文无关的表示,隐藏层旨在学习与上下文相关的表示。而BERT的的强大之处就在于其能够学习上下文的语义。因此将嵌入大小E与隐藏层大小H分开,能够根据建模需求更有效地利用模型参数的总量,即我们可以在隐藏层中使用更多的参数来获得上下文相关信息,而在词嵌入中使用较少的参数。(H远大于E)
- 同时,如果E == H,增加H会增加嵌入矩阵的大小(V*E),结果是模型参数过亿,而这些参数大部分都会被稀疏的更新。
因此ALBERT采用分解嵌入参数化,相比于BERT直接将one hot向量投影投影至H的隐藏层,ALBERT先将其投影至大小为E的低维嵌入空间,然后再将其投影至隐藏层。通过使用这种分解,我们将嵌入参数从 O(V × H) 减少到 O(V × E + E × H)。当H远大于E时,这种减少是很显著的。BERT在tokenization选择了wordpiece嵌入,即子词嵌入。子词相比于全词在文本中分布更加均匀,不同的子词采用定长的嵌入也是合理的。
跨层参数共享(Cross-layer parameter sharing)
跨层共享参数有许多种方法,例如仅共享前馈网络参数,仅共享注意力参数。在ALBERT中,默认共享所有参数。嵌入是震荡的,而不是收敛的(?)
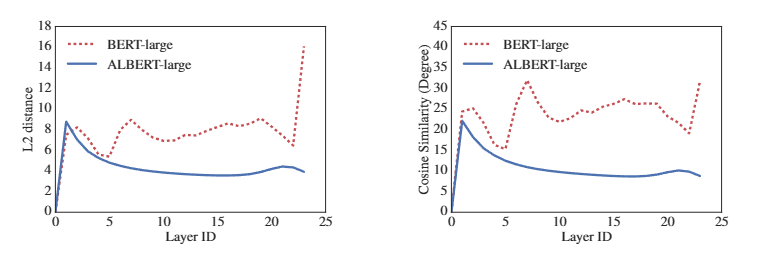
下图显示了使用 BERT-large 和 ALBERT-large 每一层的输入和输出嵌入的 L2 距离和余弦相似度。我们观察到 ALBERT 从层到层的转换比 BERT 更平滑。这些结果表明权重共享对稳定网络参数有影响。尽管与 BERT 相比,这两个指标都有所下降,但它们仍然不会收敛到 0,即使在 24 层之后。
句间连贯性损失(Inter-sentence coherence loss)、
BERT中的NSP是一种二分类损失,旨在预测两个句子是否在原始文本中连续,然而这被证明是不可靠的,详情见。
可能的原因是,在NSP任务中,正样本是连续的段落,负样本是来自不同文档的段落。这意味着,模型在判断负样本时,可能更多的是依赖于两个段落是否讨论相同的主题,而不是是否连贯。因此,这个任务更像是在进行主题预测,而非更复杂的连贯性预测。这种主题预测任务难度较低,导致模型在学习时主要关注的是主题上的相似性,而不是更难的连贯性判断。这就是为什么NSP任务可能不如预期有效,因为它与MLM任务学到的内容有较多重叠,没有带来额外的显著提升。
ALBERT仍然保留了句间建模,但是以连贯性的方式提出。也就是作为正样本句子对不在相邻,负样本就是将二者互换,旨在使模型学习关于话语级连贯性的更细粒度区分。
实验
暂略