论文笔记1,Bert框架。原文。
本文介绍了一种新的语言表示模型(language representation model) ,BERT,即Transformer的双向编码器。
概述
BERT框架主要有两个步骤,分别是预训练pre training,和微调fine tuning。预训练时模型在不同任务上进行无监督训练,微调则采用预训练的参数作为初始化参数,再针对下游任务的标注数据微调,即每个下游任务都有其独特的微调模型。结构如下图所示。
Transformer的细节不再赘述。在BERT中,层数-即Transformer的块数为L,隐藏层为H,自注意力头为A。具体数值由bert版本决定。
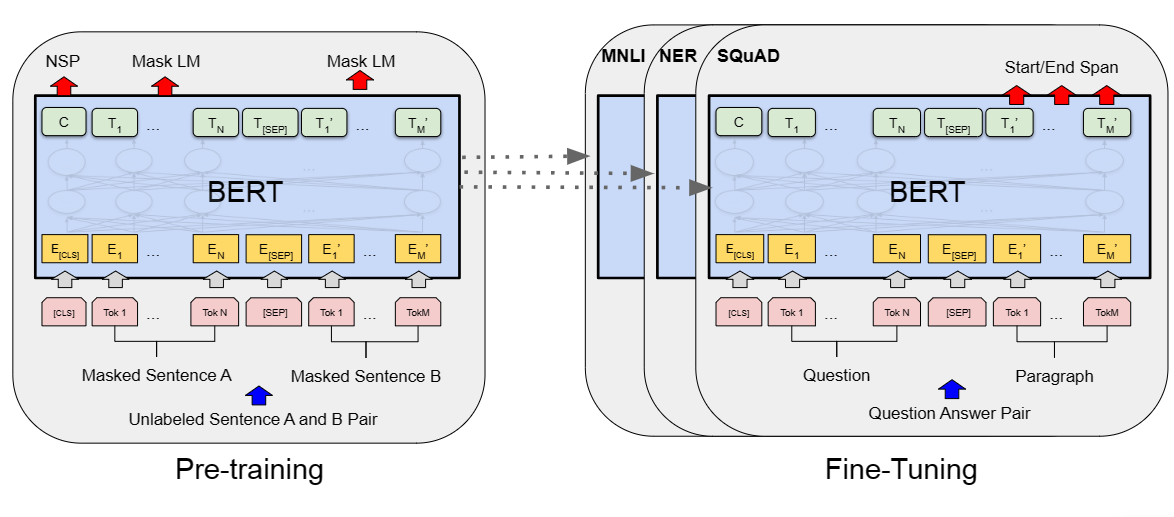
输入
如上图所示,BERT的输入是一个token序列,其表示能够适应 单个句子 和 一对句子 两种格式的输入(这里的句子指任意跨度的连续文本,而不是语义上的句子)。具体来说,每个序列头部是[CLS]标记符,该token对应的最终隐藏状态用作分类任务的聚合序列表示(?)。如果输入是句子对,句子间添加一个标记符[SEP],并且为每个token添加一个学习嵌入,以指示其属于句子A或者B。最后每个token转化为长为H的向量。
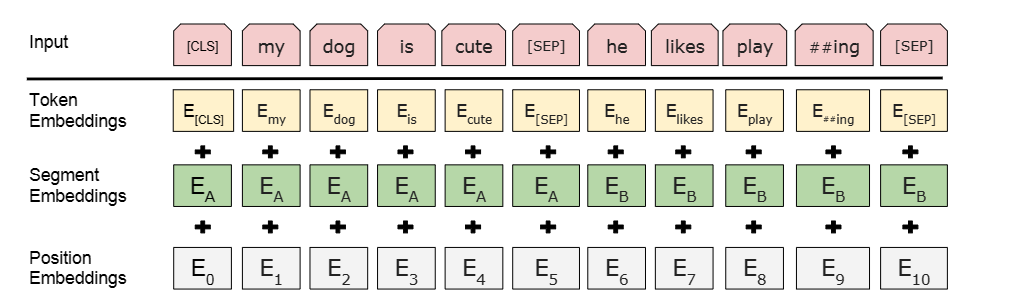
一个token的最终向量是由token,段segment,位置position的嵌入求和得到的,如下所示。
预训练
可以证明的是,预训练(pre training)的语言模型可以改善许多NLP任务。将其运用于下流任务主要有两种策略,基于特征(feature based)和微调(fine-tuning)。feature based的模型如ELMo。fine tuning的模型如GPT( Generative Pre-trained Transformer )。上述的方法共享目标函数,并且使用单向的语言模型来学习通用语言表示。
BERT改进了GPT的单向架构,注意两个方向的上下文。
masked LM
为了训练深度双向表示,随即屏蔽一些输入token,然后对其进行预测,即MLM。具体来说,我们在每个序列随机屏蔽15%的token。
矛盾的是,在微调期间不会出现MASK。因此采用如下的策略缓解这种情况——在屏蔽token时,80%替换为MASK,10%替换为一个随机token,10%不改变token。之后的嵌入向量借助交叉熵损失来预测原始token。
Next Sentence Prediction
本任务旨在训练模型能够理解两个句子之间的关系。
具体来说,预训练选取句子A和句子B时,50%B是A的实际下一句,50%句子B是语料库中的随机预料,图1中的C向量就被用于NSP。通过Label的值实现(IsNext/NotNext)。
数据
来自BooksCorpus,800m词汇。和英文Wikipedia,2500m词汇。
微调
对于每个下游任务,将其特定的输入输出插入BERT即可,并端到端的微调所有参数。如果输入只有一个句子,比如文本分类或者序列标注,则另一个句子设置为空。
实验
暂略